
センサデータ×データ解析による設備保全DX
第3回 予知保全の実現にむけたデータ解析―正規分布を活用した手法(2)
3. ホテリングのT2法の実際―人工データによる検証
本項は、人工データを用いて外れ値検知・異常検知を実施するフローを示し、ホテリングのT2法の活用がイメージしやすいようにすることを目的としています。実施フローは第2回の“2. 予知保全におけるデータ解析の進め方”のStep2~4に対応する部分もあるため、ここではその表記に従います。
3.1 使用する人工データと、異常の観察・分類(Step2・3)
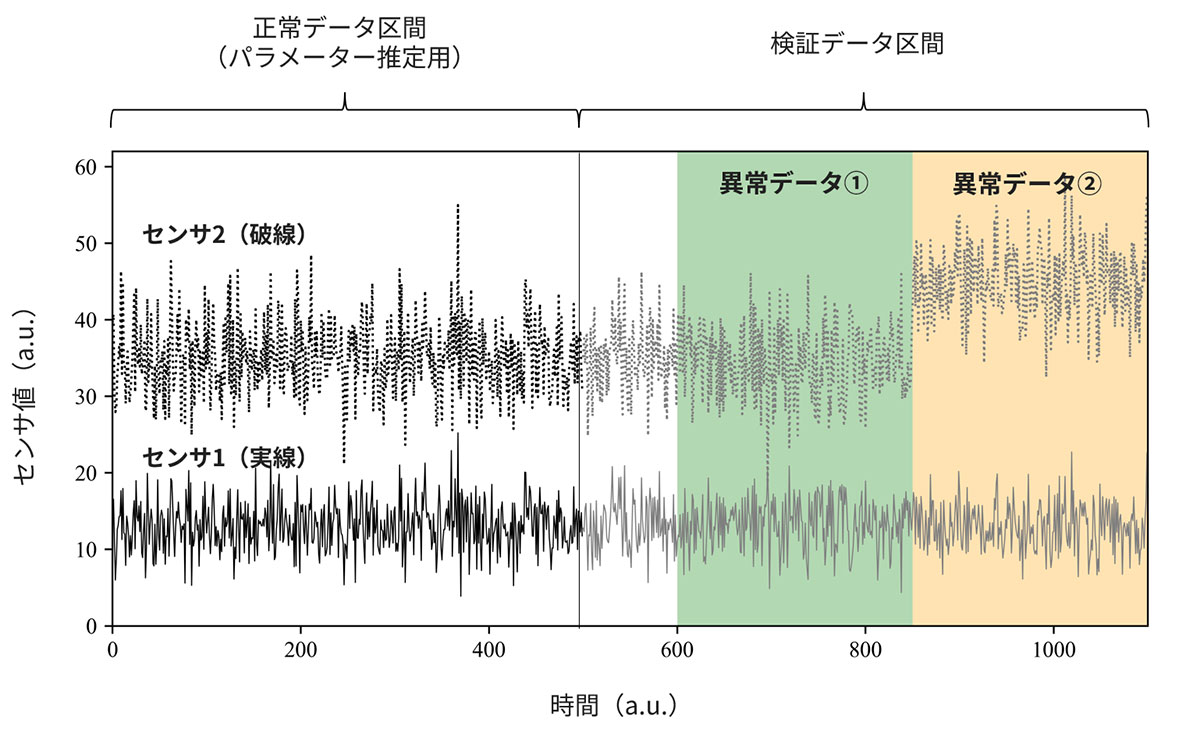
図8に検証で使用する、2種類のセンサ(センサ1・2)を模した人工データの時系列プロットを示しています。データの前半部が正常データ、後半部が異常を含む検証データとしており、異常は2パターン用意しています(異常データ①:緑色、異常データ②:橙色)。人工データは正規分布から発生させた乱数をもとにしていることから、今回はデータが正規分布に従うことはあらかじめ分かっていることとします。
Step2・3に従い異常を分類してみると、異常データ②は特にセンサ2の値においてドリフトをともなう異常のように見受けられます。このプロットのみでは、異常データ①は異常として認識するのは困難です。一旦ここでは、異常検知という形でホテリングのT2法を適用することを考えてみます。以降では、1次元正規分布・多次元正規分布を用いたホテリングのT2法をそれぞれ、1次元・多次元ホテリングのT2法のように呼称しています。
3.2 手法の適用と結果の評価(Step4)
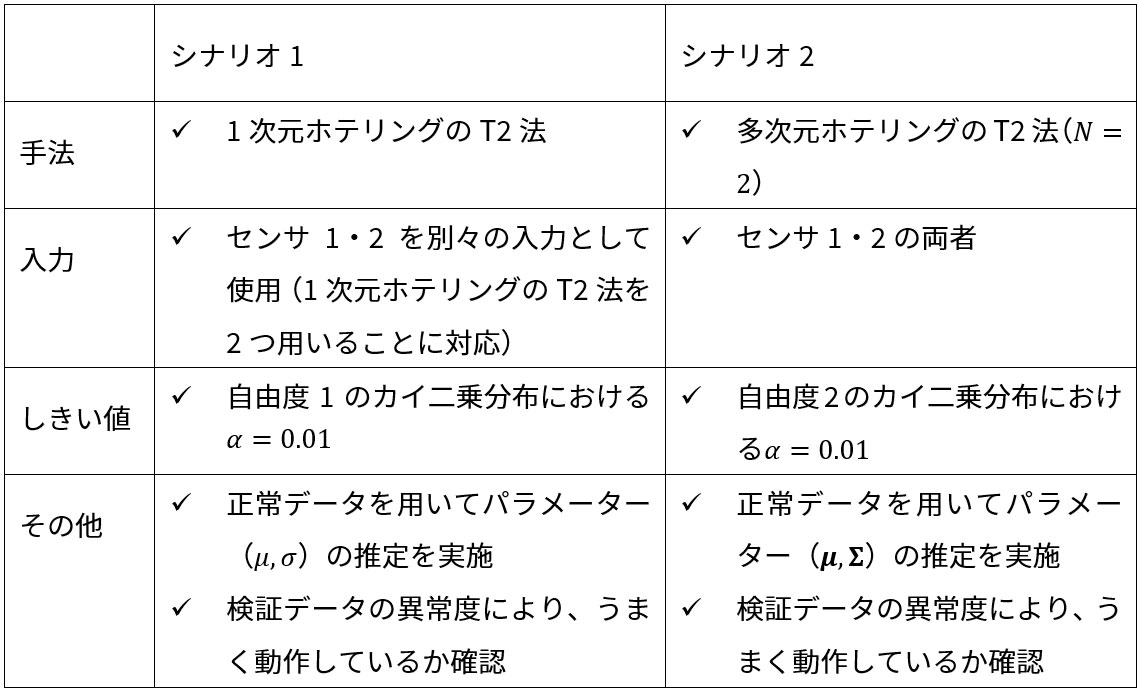
今回の事例では、1次元・多次元(𝑁=2)ホテリングのT2法の違いを確認するため、以下2パターンのシナリオ検証を実施しました(表2)。各シナリオの結果は図9に示しています。
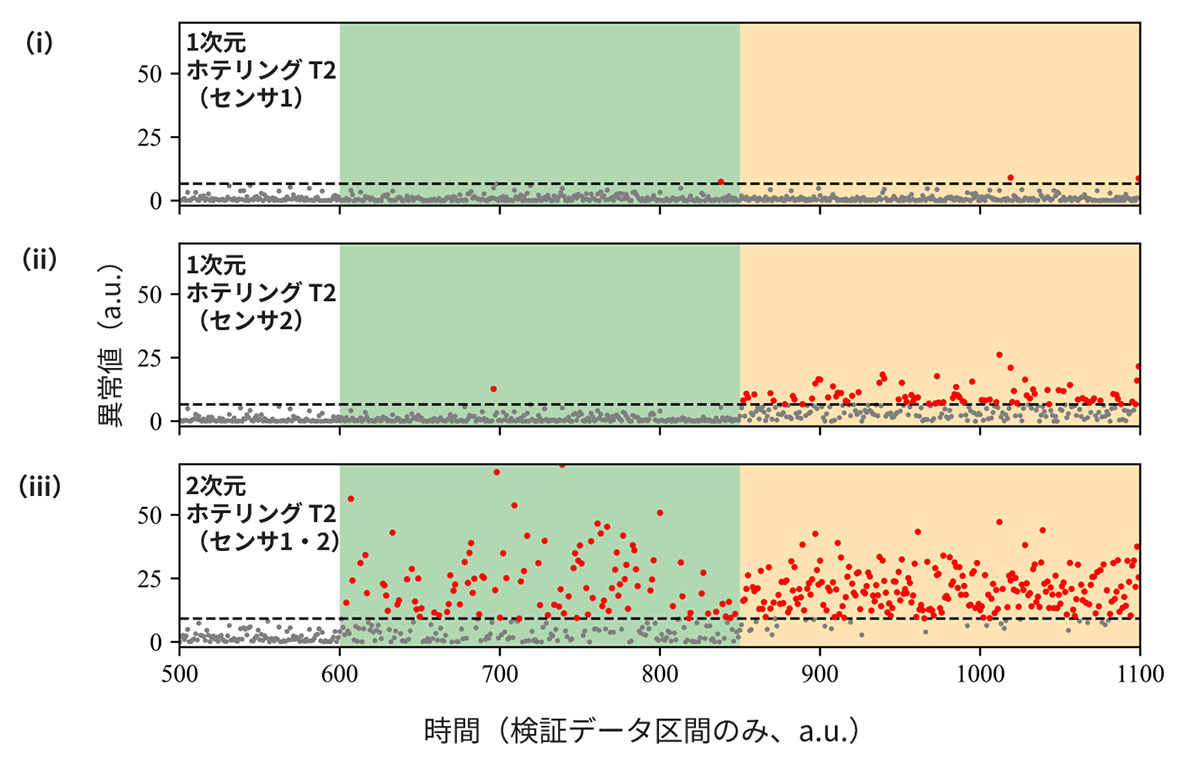
シナリオ1の結果(図9-(i)&(ii))を見ると、異常データ①はまったく異常を検知できていません。異常データ②の場合はセンサ2側でデータの一部をうまく異常と判定していますが、ほとんどは異常と判定できていません。一方、シナリオ2の結果(図9-(iii))に目をむけると、異常データ①・②ともに、シナリオ1と比較してかなり多くのデータを適切に異常と判定しており、特に異常データ②ではほぼすべてのデータを異常と判定することに成功しています。この比較から、多次元正規分布を仮定したホテリングのT2法の優位性が理解できると思います。
本記事の最後に、シナリオ1とシナリオ2でなぜその性能に大きな差が生じるのか?その理由について説明したいと思います。この点は、センサデータ1・2を描画した散布図上に各シナリオにおけるしきい値と異常判定範囲を見ることではっきりと確認することができます(図10)。
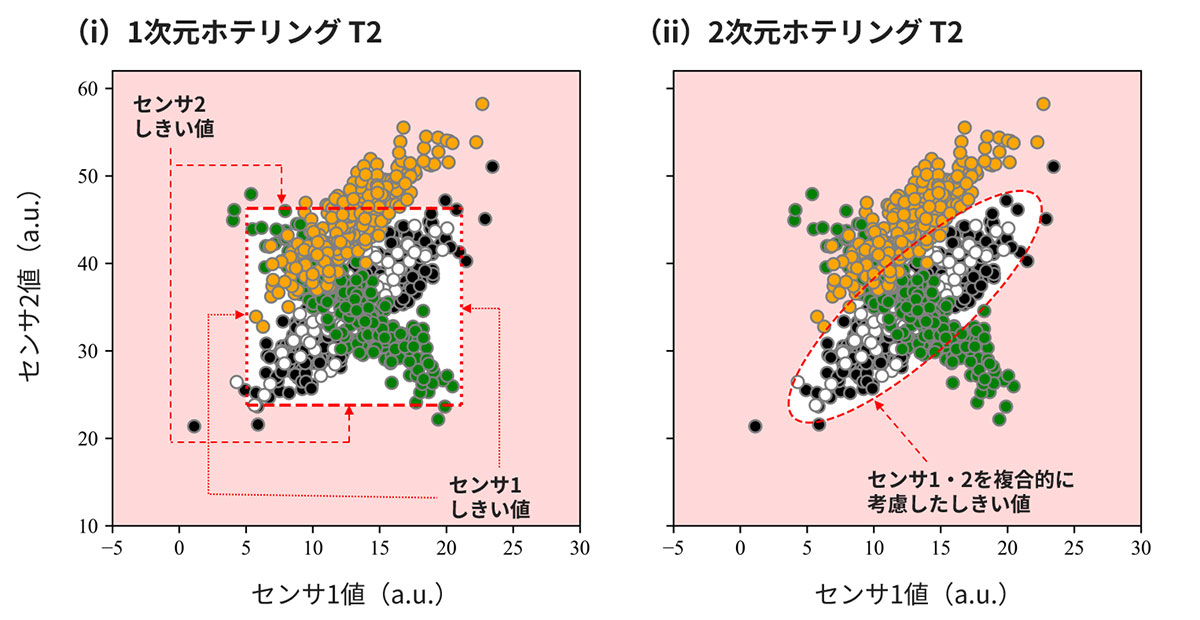
散布図から、正常データ(黒色)においてセンサ1とセンサ2の値が正の相関*6を有していること、その一方で異常データ①(緑色)はセンサ値の範囲が正常データと同一であるものの相関が負となっている、異常データ②(橙色)は正の相関ながらセンサ2の値が正常データよりやや大きい値にシフトしており、いずれも正常データから乖離した挙動を示していることが分かります。
ここで着目してほしいのが、シナリオ1および2のしきい値範囲です。シナリオ2では、しきい値範囲が正常データをかこむ楕円状となっていますが(図10-(ii)白色背景)、これは多次元ホテリングのT2法がセンサ1とセンサ2の有する相関関係をうまくとりこんでいるためです(図5-(ii)&(iii)―Part 1の2.2項)。そのため、相関関係の異なる異常データ①やセンサ2の値がシフトしている異常データ②を適切に異常と判定することが可能となっています(図10-(ii)赤色背景)。
これと対称的であるのがシナリオ1です(図10-(i))。シナリオ1の1次元ホテリングのT2法では、センサ1・2を別々の入力としているためデータ間の相関構造は一切考慮せず、各センサ値のとりうる範囲のみで異常の判定を下します(図10-(i)白色背景)。そのため、特にセンサ値の範囲が同一である異常データ①についてはまったく異常を判定することができないという結果となっているのです。
*6 データ間における関係性や規則性をあらわす概念のひとつ。一方の数値が増加したとき、もう一方の数値が増加する場合を正の相関、減少する場合を負の相関と言う。
4. おわりに
本記事では、異常度の定義や異常判定の仕組みから導入を行い、その後ホテリングのT2法の理論と実際について解説を行いました。ところどころ数式を使用しているため一度ですべてを理解するのは難しいかもしれませんが、具体事例を通してホテリングのT2法の全体像やその仕組みについて把握できたのではないでしょうか。
異常検知に限りませんが、データ解析手法を用いる際はその仕組みについて把握しておき、自身の課題にあわせて適切な手法を選択できるようにしておくことが重要となります。仕組みを理解するには時間や労力がかかると思いますが、ホテリングのT2法についてはぜひ本記事をなんども読み返す中で、理解を深めていただけると幸いです。
[補足]数式に関連した定義および記法
数式を取り扱うにあたり、スカラー、ベクトル、マトリックスを取り扱う必要があるため、その定義と記法を表3にまとめています。特に、ベクトル・行列やその操作に関連した記法は表4にまとめています。そのほか、確率分布に関連した記法は表5に示します。
(表中記載内容の数学的な詳細や、文中においてあらわれる指標の詳細や定義に興味がある方は、線形代数や統計学などの成書にあたることをおすすめします。)

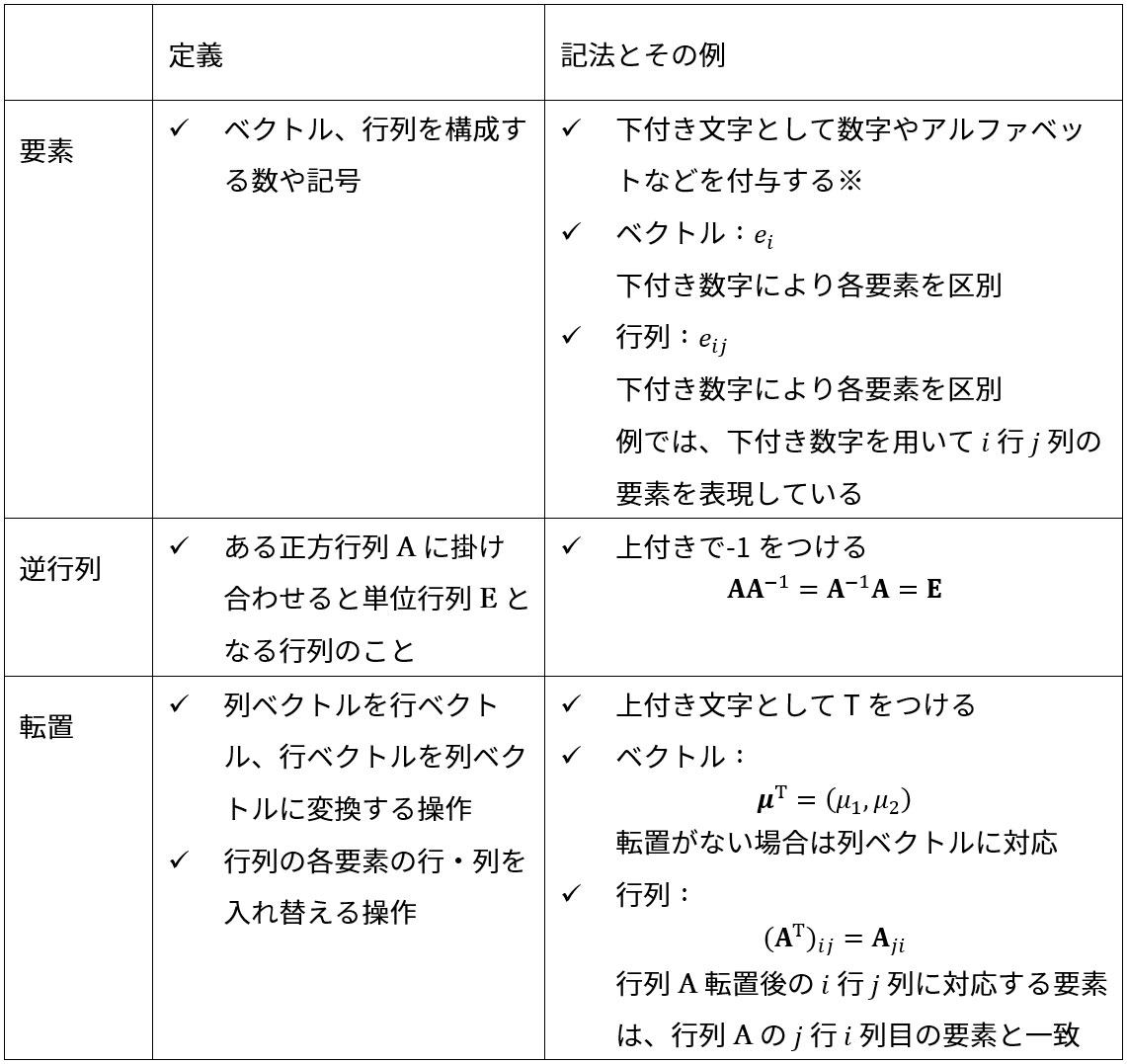
Note:ベクトル、行列の要素以外の目的でも下付き数字・記号を付与する場合はあるが、その際は都度文中で定義を行う。
