センサデータ×データ解析による設備保全DX
第3回 予知保全の実現にむけたデータ解析―正規分布を活用した手法(1)
「センサデータ×データ解析による設備保全DX」シリーズ第2回では、予知保全で用いられるデータ解析技術やデータ解析の進め方について解説を行いました。第1回の内容とあわせることで、予知保全とデータ解析を組み合わせる上での重要なポイントをおさえることができたのではないでしょうか。「センサデータ×データ解析による設備保全DX」シリーズでは、予知保全で用いる代表的なデータ解析手法の解説を行う、データサイエンスに特化した内容を取り扱っており、シリーズ第3回の本記事でスポットライトをあてる手法は、シンプルかつ強力な、正規分布を活用したホテリングのT2法です。
はじめに―本記事の構成
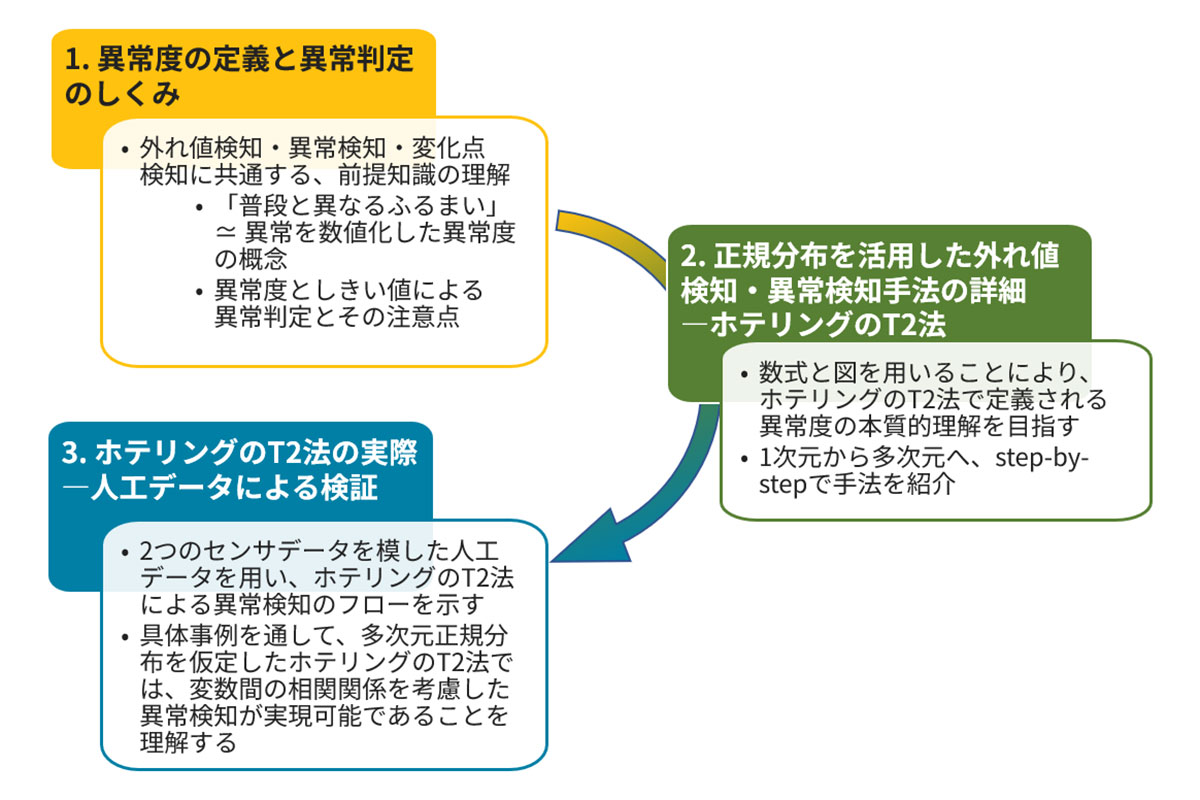
図1に本記事の構成フローを示します。1項では本シリーズの手法紹介で共通する内容を取り扱っています。手法の詳細に立ち入るために数式を用いる場合もありますが、イメージ図や人工データを使った具体事例を通して、ホテリングのT2法の仕組みと実際を分かりやすく解説しています。
1. 異常度の定義と異常判定の仕組み
本記事や以降の記事で取り扱う、外れ値検知・異常検知・変化検知のいずれの手法も共通して、「普段と異なるふるまい」を示すデータ点、もしくはその集合を外れ値・異常・変化として、選択的に見つけ出すことを目的としています(外れ値検知・異常検知・変化検知の概念については第2回を参照)。これを手法として実現するには、「普段と異なるふるまい」という概念、つまり異常を、うまく数値化・定量化する必要があります。
異常を数値化・定量化した指標は、一般に異常度と言います。異常度は、普段のふるまいをしているとされるデータ点・集合(正常データ)を基準として、あるデータ点・集合がどの程度乖離しているかを、正の値をとる数値指標として定義したものです(図2)。異常度を導入することにより、あるデータの異常度が小さければそれは普段と類似したふるまいであること、異常度が大きければ異常であることを直感的に理解することが可能となります。異常度は用いる手法により定義が異なりますが、その意味するところは上で説明した内容で共通しています。
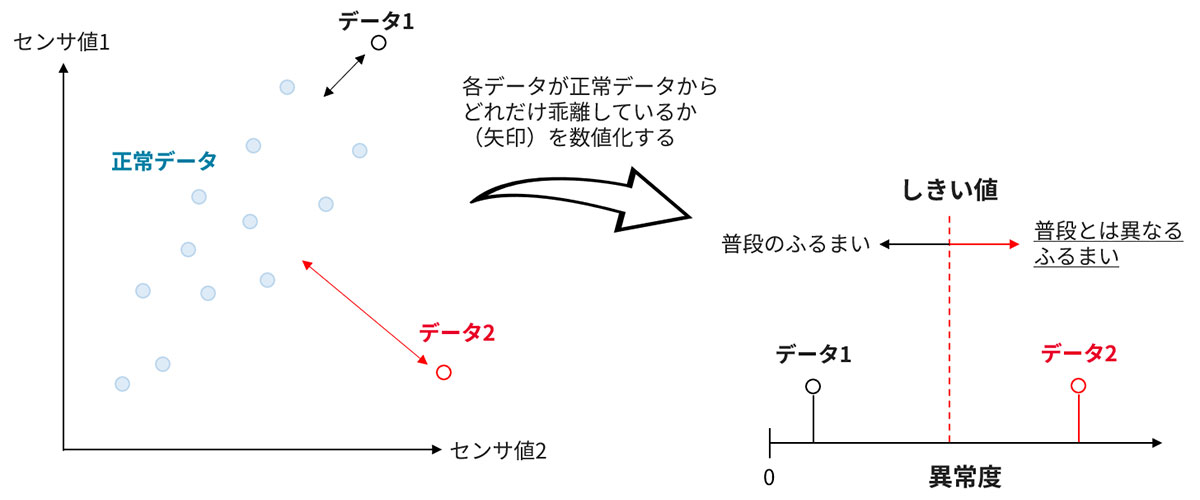
異常度を用いて最終的に正常と異常を判断するためには、正常と異常を区分けする異常度のしきい値を設定する必要があります(図2右)。しきい値の設定方法は手法によりさまざまですが、それに加えて利用者側の要望をもとに決められることも多いです(<コラム1>外れ値検知・異常検知・変化検知手法の評価指標)。重要なポイントとして、全手法に共通して汎用的に利用できるしきい値基準は基本的に存在せず、場面に応じて自身で定める必要がある、と認識しておくとよいでしょう。
以上の内容は、外れ値検知・異常検知・変化検知の個別手法を理解する上で最低限おさえておくべきポイントになります。これらの内容を念頭に置きながら、次項では外れ値検知・異常検知の代表格である、正規分布を活用した手法の詳細にせまっていきます。
2. 正規分布を活用した外れ値検知・異常検知手法の詳細―ホテリングのT2法
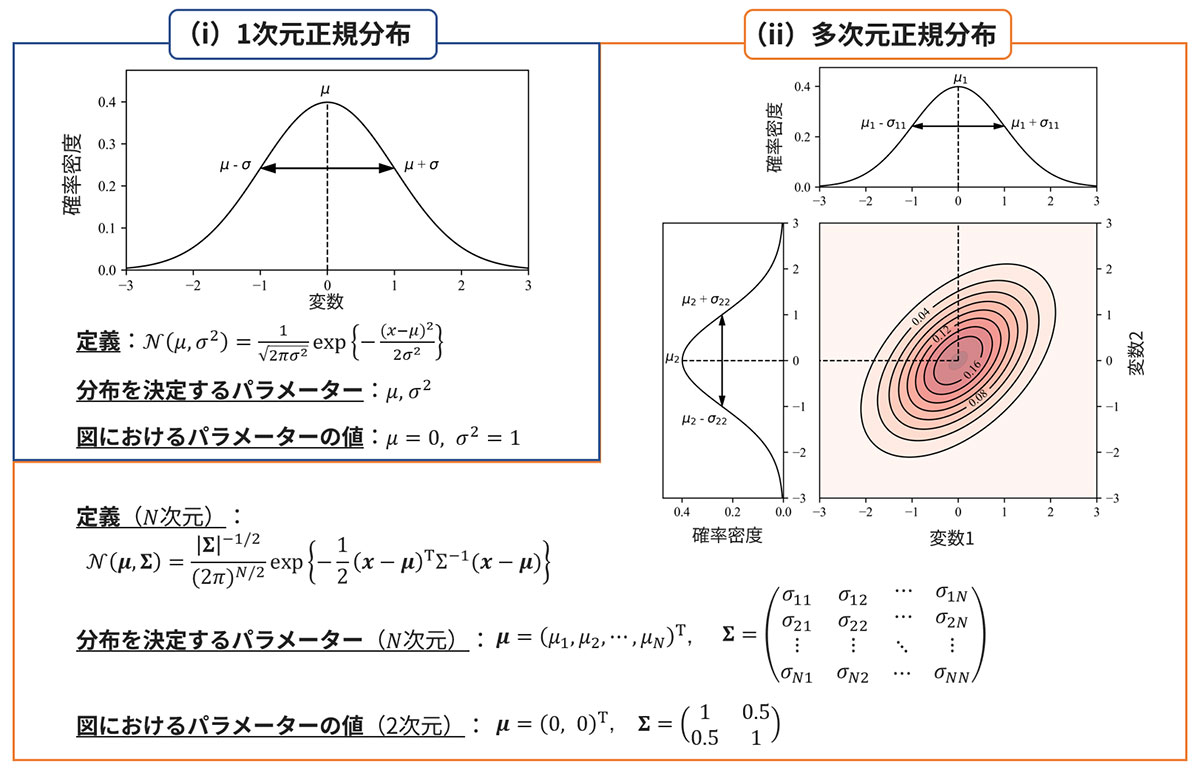
正規分布を活用した外れ値検知・異常検知手法は、ホテリング(Hotelling)のT2法と呼ばれています。この手法では、手元にある正常データが1次元の場合は1次元正規分布(図3-(i))、多次元の場合は多次元正規分布(図3-(ii))に従うと仮定し、異常度の定義としきい値設定を行います。
この項では、はじめに1次元正規分布*1を用いたホテリングのT2法を説明した後、それをもとに多次元正規分布*1へ拡張したホテリングのT2法の説明を行います。最後に手法の実運用におけるメリット・デメリットを示します。順を追って読んでいくことにより、手法の理解が深まる構成をとっています。
*1 1次元正規分布、多次元正規分布はそれぞれ、単変量正規分布、多変量正規分布とも呼称されます。
2.1 1次元正規分布における異常度としきい値
1次元の正常データが、1次元正規分布(図3-(i))に従うと仮定します。正規分布の性質から、このときの正常データは、𝜇を中心とし𝜎程度の広がりをもった値から構成されることとなります。正規分布のパラメーター𝜇と𝜎は、手元の正常データから事前に推定する必要があります。
上記を仮定すると、あるデータ点𝑥の異常度𝑎(𝑥)は式(1)に定義することができます。あわせて、異常度の概念を説明する具体例を図4に示します。
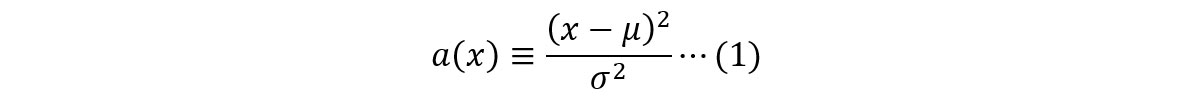
図4では、2種類の正常データがそれぞれ正規分布𝒩₁、𝒩₂に従うとしています。以下では、各分布に対しデータ点𝑥₁と𝑥₂が存在する例を用いて、異常度という指標と、しきい値の概念理解を目指します。この例では、𝑥₂は正常なデータ、𝑥₁は異常なデータを想定しています。
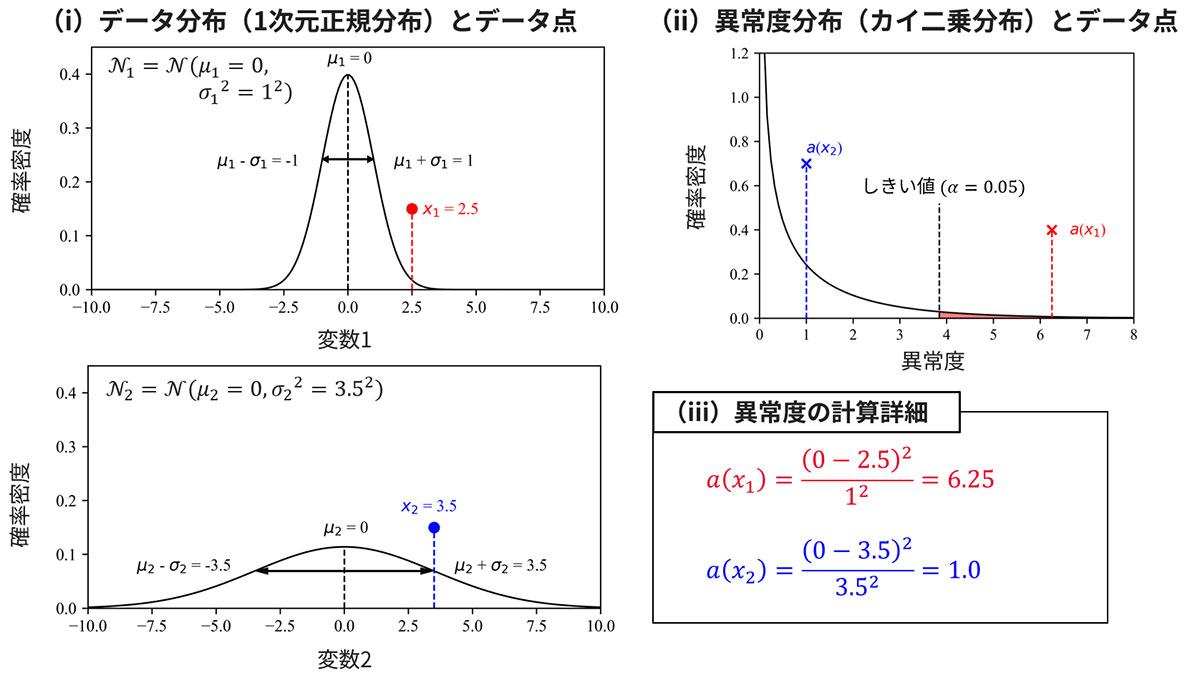
図4-(i)と式(1)から、異常度の分子項は、あるデータ𝑥と正常データの従う正規分布の中心𝜇との距離に対応しており、これは「普段と異なること」を愚直に数値化した項であると理解できます。ただし、分子項のみだと、正規分布の広がり𝜎₁、𝜎₂を考慮できていません*2。この点をうまくカバーする役割を担うのが分母項になります。実際に𝑥₁と𝑥₂の異常度を算出した結果を図4右に示していますが、想定どおり𝑥₂と比べ𝑥₁の異常度はきわめて大きい値をとっています。これは、異常度が分布の広がりをうまく考慮できていることをはっきりと示しています。
しきい値設定には、異常度そのものが自由度(1, 𝑛−1)のF分布、もしくは自由度1のカイ二乗分布(<コラム2>カイ二乗分布とF分布)という確率分布に従う性質を利用することができます。F分布の自由度であらわれる𝑛は、パラメーター𝜇と𝜎の推定に使用した正常データの個数に対応します。
図3-(ii)には異常度が近似的に従う、自由度1のカイ二乗分布を示しており、その形状は異常度が大きくなるほど確率密度が小さくなっています。つまり、大きな異常度をもつデータはきわめて低い確率でしか発生しないレアな事象であると解釈できます。確率分布を用いる場合、あるデータの異常度のレアさがどの程度であれば異常とみなすのか、その確率をもとにしきい値を設定します。
すでに述べているとおりですが、汎用的に機能するしきい値は存在せず、問題に応じて適切な値を設定する必要があります。慣例的には、カイ二乗分布の上側5%や1%水準*3がよく用いられ、𝛼=0.05や𝛼=0.01のように表記されます。図4-(ii)に示す例はしきい値に上側5%水準を採用しており、あるデータの異常値がこの水準より大きな値をとる場合(図4-(ii)赤色領域)、そのデータは異常であると判定します。
上記ではしきい値設定に確率分布を利用した方法について述べましたが、そのほかにも異常度の大きさそのものを利用した分位点(e.g., 上側1%点)を用いる方法などさまざまな決め方が存在しています。
*2 分子項のみを異常度と定義すると、データ点𝑥₂の方が異常であるという、想定に反した結果になります。
*3 その異常度を示すデータの生じる確率が5%もしくは1%に対応するカイ二乗分布の値になります。
2.2 多次元正規分布における異常度としきい値
正常データが多次元(𝑁>1)の場合は数式が複雑になりますが、考え方自体は1次元の場合と大きく変わりません。データ次元が𝑁次元、正常データが多次元正規分布に従うとし、そのパラメーター𝝁と𝚺⁻¹を手元にある正常データから事前に推定しておきます。このとき、あるデータ点𝒙=(𝑥₁, 𝑥₂, ⋯, 𝑥𝑁)Tの異常度は以下に定義されます。
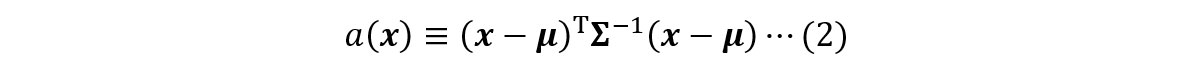
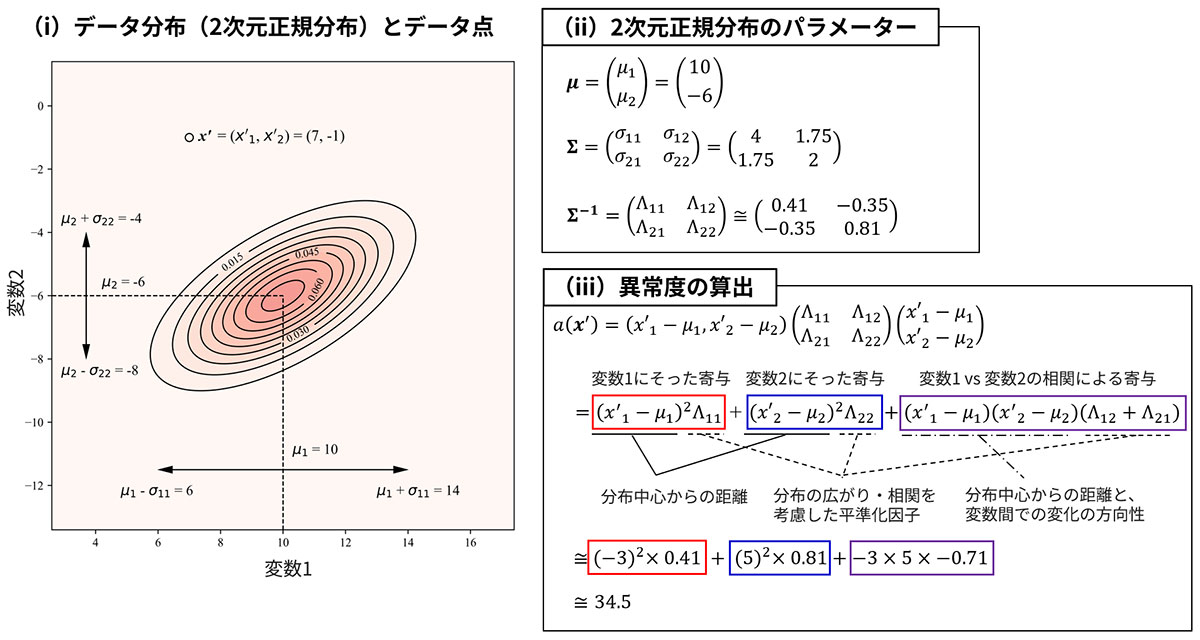
式(1)のときと同様に、式(2)の計算の具体例(𝑁=2)を図5に示します。式(2)で2回登場する(𝒙−𝝁)は式(1)の分子項、𝚺⁻¹は式(1)の分母項に対応するもので、その意味は式(1)とほとんど変わりません。式(1)の分母項は分布の広がりを平準化する役割があると書きましたが、それに加え、式(2)の分母項はデータ点𝒙を構成する各要素が異なる単位であったとしても、それらの情報を統合できるよう平準化したり*4、各要素間で相関がある場合にその影響をうまく反映するはたらきをしています。このことは、具体的な計算を実施するとよく理解することができます。計算の詳細に興味がある方は、図5-(ii)&(iii)の計算例を参照ください。特に、相関の影響についての議論は、Part 2の3項で人工データを用いた具体例とともにあらためて説明を行います。
異常度を算出した後の手続きは、1次元の場合とまったく同じとなります。唯一異なるのは確率分布の自由度で、多次元正規分布の場合、異常度は自由度(𝑁, 𝑛−𝑁)のF分布、もしくは自由度𝑁のカイ二乗分布に従う、という点のみです(<コラム2>カイ二乗分布とF分布)。F分布の自由度であらわれる𝑛は、𝝁と𝚺⁻¹の推定に使用した正常データの個数に対応します。
*4 たとえば、𝒙=(𝑥₁, 𝑥₂)Tのとき、𝑥₁は振動センサ値、𝑥₂は温度センサ値と仮定します。いずれも単位・とりうる数値範囲はまったく異なりますが、式(2)の分母項によりこの2つの値をうまく加味した異常度を算出できるようになっています。図5や、Part 2の3項にその例を示しています。
2.3 ホテリングのT2法のメリット・デメリット
ここまでホテリングのT2法の詳細を解説しましたが、実運用上関連するメリット・デメリットについては以下の表1にまとめています。デメリットについては、その対応策をあわせて記載しています。
| メリット | ・手法の仕組みが明瞭で、結果の解釈が容易である ・多次元データを取り扱え、その相関構造を考慮できる |
|---|---|
| デメリット | ・正常データが正規分布に従わない場合(e.g., 多峰性を有する分布)や 極端な外れ値が存在する場合、性能が低下する ・データ数に対しデータ次元が大きすぎると、性能が低下する(次元の呪い) ・異常が生じた場合、どの変数の影響が大きいかを算出できない |
| デメリット への対応策 | ・より柔軟な手法の適用を考える(e.g., 多峰性を有する分布:混合ガウスモデル(GMM))、 また事前処理で正常データから外れ値をとりのぞいておく ・不要な変数を事前に削除する、もしくは次元削減により次元の呪いを回避する (e.g., 主成分分析(PCA)、部分最小二乗回帰(PLS)) ・異常に対する各変数の寄与を算出できる手法を用いる(e.g., マハラノビスタグチ法) |
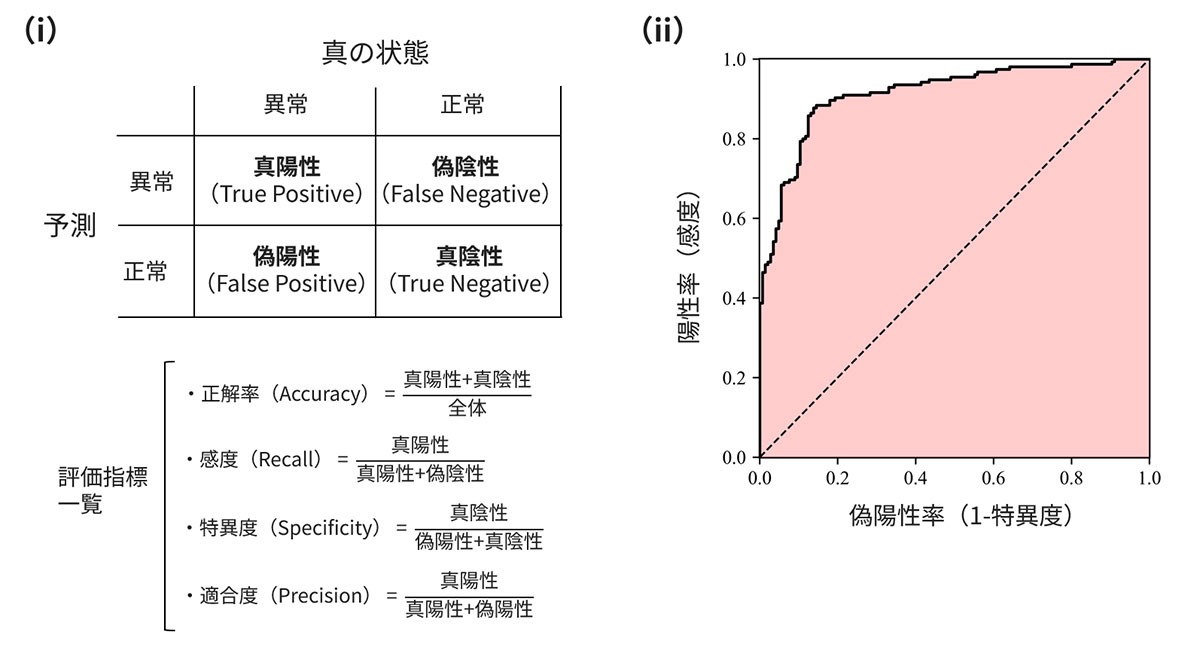
<コラム1>外れ値検知・異常検知・変化検知手法の評価指標
外れ値検知・異常検知・変化検知ではその結果を目視確認することで、定性的判断が可能な場合はある一方で、結果を定量的に評価することも同じく重要です。結果の定量的評価をする上で欠かせないのが評価指標になります。図6には、外れ値検知・異常検知・変化検知で用いられる代表的な評価指標を示しています。
このような評価指標を用いることにより達成すべき目標を定義できるため、予知保全の利害関係者とのコミュニケーションを円滑にできる、異なる手法で得られた結果が比較可能になるなど、その恩恵は大きいです。
その一方で、予知保全において定量評価したいポイントを適切に評価可能である評価指標を使う必要がある点は、注意が必要です。一般的に頻用される指標は図6に示すとおりですが、どの評価指標を使うべきかはケースバイケースです。評価指標を選択する際は、あらためて予知保全の目的・何を評価すれば目的が達成されるのか再確認すること、類似の事例でどの指標が使われているのか確認すること、が重要となってきます。必要があれば、独自の評価指標を作成、評価に使用することも選択肢として存在することは認識しておくべきです。
<コラム2>カイ二乗分布とF分布
ホテリングのT2法の異常度の従う分布としてあらわれるカイ二乗分布とF分布は、以下に示す性質を有する分布になります。
[カイ二乗分布](カイはギリシア文字の𝜒)
ある確率変数𝑧が標準正規分布*5に従う場合、その分布より独立に得られた𝑚個の変数𝑧𝑖(𝑖=1~𝑚)の二乗和は自由度𝑚のカイ二乗分布に従うとして、以下に定義されます。
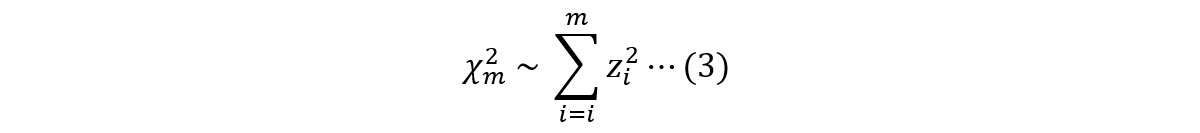
*5 𝒩(𝜇=0, 𝜎²=1)で示される正規分布のこと。任意の正規分布𝒩(𝜇, 𝜎²)に従う変数𝑥は、以下式(3)に示す標準化という操作により標準正規分布に従う変数𝑧に変換することが可能である。
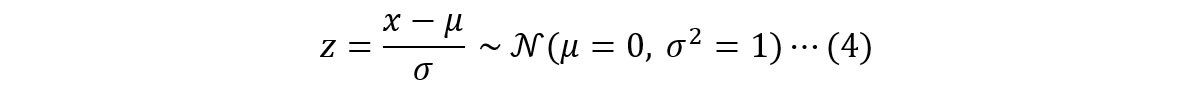
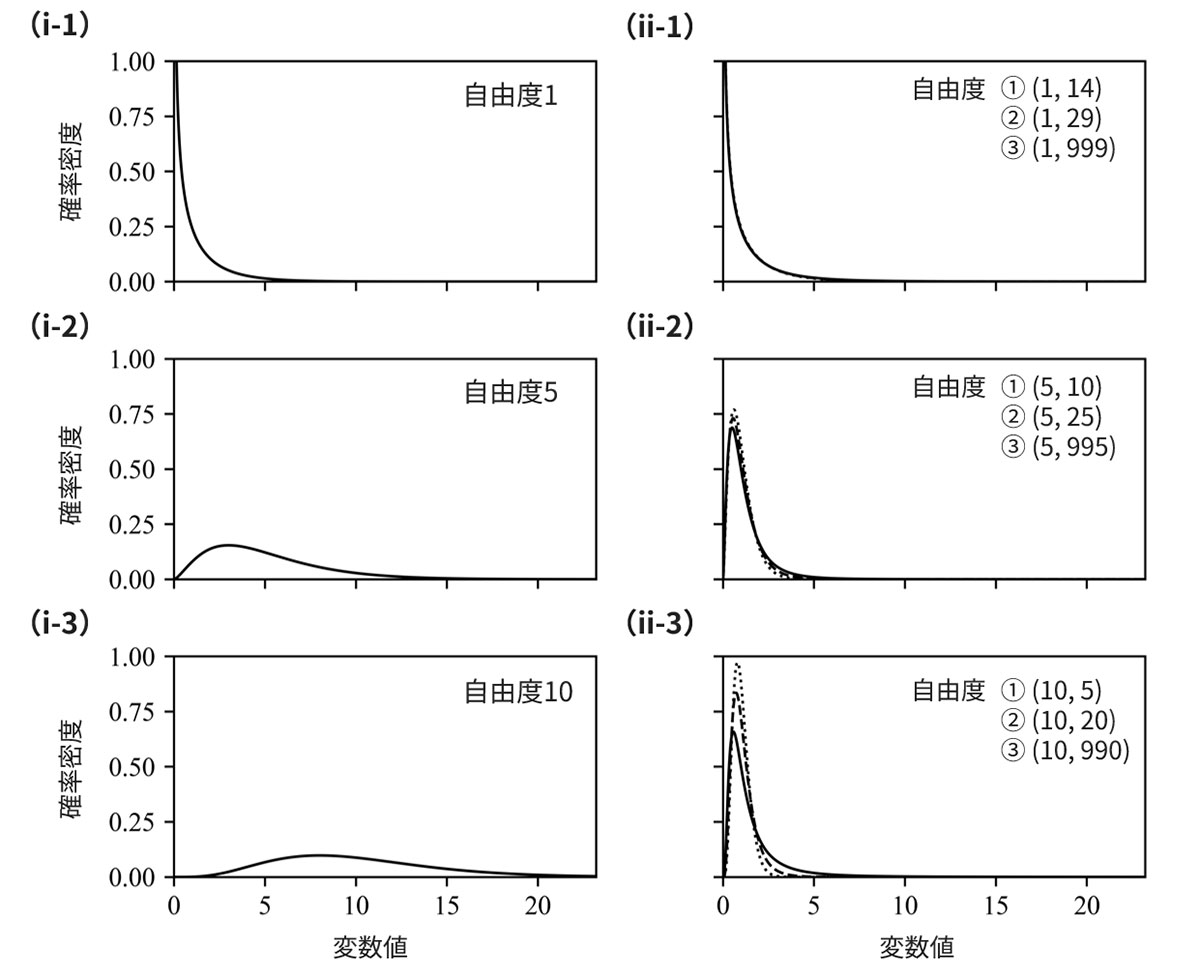
自由度は分布形状を決定するパラメーターです。自由度をふった場合におけるカイ二乗分布の形状は図7-(i)に示すとおりです。
カイ二乗分布は、分布の適合度検定や独立性の検定などで使用されます。ホテリングのT2法において、正常データ数𝑛が十分に大きい場合、異常度は近似的にカイ二乗分布に従うと仮定することができます。
[F分布]
ある確率変数𝑢, 𝑣が相互に独立である自由度𝑝, 𝑞のカイ二乗分布に従う場合(𝑢~𝜒𝑝², 𝑣~𝜒𝑞²)、自由度𝑝, 𝑞のF分布は以下に定義されます。
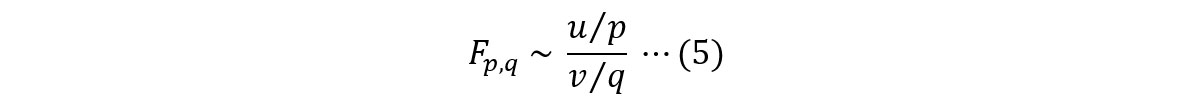
自由度は分布形状を決定するパラメーターです。自由度をふった場合におけるF分布の形状は図7-(ii)に示すとおりです。
F分布は、2つのデータ集合の分散が等しいか検定するF検定などで使用されます。ホテリングのT2法において、異常度に適切なスケール因子をかけあわせた数値がF分布に従うと仮定することができます。