
生成AIにも関連するマルチモーダルAI―人のように複数の情報・データを統合して処理を可能とするAI
INDEX
1. 生成AIとマルチモーダルAI
AI技術は急速に進化しており、私たちの生活やビジネスなどの在り方を変えつつあります。そのAI技術において、現在とくに注目を集めているAIとして「生成AI」と「マルチモーダルAI」があります。生成AIはテキスト/画像/音楽など、複数の形式のデータを自動的に生成・出力する能力をもち、これまで人間が担ってきたクリエイティブな作業の支援を可能とするAIです(<コラム>生成AI(Generative AI)とは参照)。
一方、マルチモーダルAI(Multimodal AI)とは、入力するデータ(モダリティ*1)の形式が複数存在するAIのことをいいます*2。たとえば、“テキスト”と“画像”といった異なるデータを入力とし、それらのデータを統合して予測を実施するAIは、マルチモーダルAIの代表例といえるでしょう。
マルチモーダルAIは複数のデータを統合し利活用できるため、従来のAIや生成AIなど、幅広い対象において活用されると予想されています(<コラム>マルチモーダルAIとシングルモーダルAI参照)。
そこで本記事では、先進的なAI技術であるマルチモーダルAIについてとりあげ、その変遷と活用事例などについて解説します。
*1 マルチモーダルの「モーダル」は、データを意味するモダリティ(Modality)の形容詞であり、したがってマルチモーダルとは複数の形式のモダリティ(テキスト、画像、音声など)のことを示します。
*2 入力だけでなく出力も含め、異なるデータ形式を扱うことができるAI、たとえば、入力するデータと出力するデータの数がそれぞれひとつでも、入力が音声、出力がテキストとデータ形式が異なるAIをマルチモーダルAIという場合もあります。
2. マルチモーダルAIの変遷
マルチモーダルAIに関する構想や研究が始まったのは1980年代といわれています。2000年代以降は、機械学習におけるディープラーニング(深層学習)とともにマルチモーダルAIの研究も進められました。2010年代には、人間の顔の表情とテキストをAIに学習させ、画面上のアバターがテキストに合わせて表情を変えるという、マルチモーダルのAIアプリケーションが発表されています。

2015年以降では、各形式のデータの関連性を効果的に捉えるAIモデルが登場し、データ統合がより高度となったことで、複雑な処理や高度な認識が実現可能となりました。そして、2020年代に入ると、主要な生成AIサービスやAIプラットフォームにおいて、マルチモーダルAIの導入が活発化していきます。
たとえば、画像・テキストなどのデータを統合し大規模言語モデル(LLM:Large language Models)を通して、自然な言語での応答を提供する、利用者の質問から画像とテキストの2つの形式のデータを出力する、画像を説明するテキストを出力するといった活用がみられます。さらに、マルチモーダルAIを搭載したウェアラブルデバイスが発表されるなど、身近なハードウェアへの導入も進みつつあります。
こうした進展を続けているマルチモーダルAIは、このほか、自動運転技術や防犯、医療、製造・エンジニアリング、ビジネスのサポートやマネジメント、スポーツ、エンターテインメントなど、今後もさまざまな分野へ急速に浸透していくと思われます。
3. マルチモーダルAIの活用事例
1項で触れたように、マルチモーダルAIは入力として複数のデータ形式を扱えるため、さまざまな目的に対して適用可能な柔軟性の高いAIです。以下では、マルチモーダルAIの主な活用事例を紹介します。
3.1 Web分野―不正品・にせ動画を判別
身近な活用事例として、個人間売買の仲介サイトにおける偽造品を判別する―新規に出品された商品に付随するテキスト(説明文やタグ)や商品画像のデータから判別するという識別のサポートがあげられます。また、動画投稿サイトなどにおいても、映像や音声など複数のデータからフェイク動画を判別するといった活用方法もあります。
偽造されやすいブランド製品のスーパーコピーや、各国の要人や著名人を模したディープフェイク動画を精度よく判別できるよう学習させることなどで、マルチモーダルAIの判別能力はいっそう向上していくことが期待されます。
3.2 自動車分野―自動運転の制御を支援

自動車の自動運転レベル5(あらゆる場所での自動走行が可能でハンドル操作を必要としない運転システム)の将来的な実用化を目指し、さまざまな研究や検証が行われています。高度な自動運転技術の研究において、マルチモーダルAIの活用が世界で注目されています。
多数のセンサで得られる自動車の内部や外部のデータ、無線通信で得られる位置やほかの自動車や交通状況に関するデータ、搭乗者との音声データなど、多様なデータをマルチモーダルAIが統合的に処理できる能力は、自動運転の制御に欠かせない技術といえます。
3.3 医療分野―診断・治療方法を補助的に提案

マルチモーダルAIを用いて電子カルテや検査画像などのデータを統合的に解析することで、病気の早期発見や治療計画の最適化に活用する研究が医療分野で進められています。たとえば、病気の状態と経過の多角的な判断や、がんの再発時期の予測、診断や治療方法を決める際の補助となる提案を、マルチモーダルAIに出力させることが考えられています。この例においては、再診時期の予測と適切な治療方法の選択に寄与するだけでなく、適切な医療提供による医療コストの削減や属人化解消による医療従事者への負荷の軽減にもつながるといわれています。医療分野においても、マルチモーダルAIの幅広い貢献が期待されます。
3.4 防犯・監視分野―状況を判断

従来のAIを用いた防犯カメラは、映像(画像)のみをAIで解析することで状況判断をサポートしています。しかし、実際の人による監視業務では、視覚以外にも音、振動、におい、ほかの監視員とのコミュニケーションなど、多くの情報から状況を判断することが求められます。
画像や音など、複数の形式のデータを統合的に処理するマルチモーダルAIは、騒音や騒動などの迷惑行為や喧嘩、不正・違法な侵入など、このような複雑な事態でもどのような状況かの判断が可能とされています。こうした活用方法の研究と実用化が進むことにより、AIによる監視業務へのサポートが大きく向上することが期待されます。
3.5 製造・開発分野―ロボットの制御/材料開発を支援

現在、製造現場で産業用ロボットの導入が著しく増加しています。これら従来の産業用ロボットの動作は、機械的な動作角度や速度、強さなどをプログラムで指定し、また画像判別などの認識技術を組み合わせることで制御されています。一方、マルチモーダルAIを用いたロボット制御の研究が進んでおり、種々のセンサからのデータなどを統合し学習することで、従来のロボットより判断能力が向上し、より繊細な作業が可能になりつつあります。製造分野のみならず、医療や介護、農業用のロボットにも応用できる技術として注目されています。
開発分野においても、マルチモーダルAIの活用がみられます。たとえば、自らが取得した実験データや論文などで報告されている物質の化学構造や組成、計測データ(顕微鏡画像や分光スペクトルなど)を統合的に処理することで、その物質の物理・化学特性を高精度で予測でき、これを利活用することでバーチャル空間で高速に配合条件や組成の最適化などを実施することが可能となります。この技術は、マテリアルズ・インフォマティクス(MI:Materials informatics)の一種であり、新材料探索など研究開発の効率化―時間やコストの大幅な低減に寄与することが大きく期待されています。
このほかにも、生産設備に配置した各種センサデータ情報の統合による高精度な異常検知の実現や、これまで自動化が困難だったロボットによる品質検査や保全活動の自動化など、マルチモーダルAIの製造・エンジニアリングへの適用は、今後も急速に進んでいくと考えられます。
4. まとめ
ここまで、主にマルチモーダルAIの活用事例について紹介してきました。
近年、主要なAIプラットフォーム上でテキストと画像といった複数の形式のデータを扱えるマルチモーダルAIのサービスが登場しています。このようなプラットフォームが多く出現し、また高度化することで、ビジネスやクリエイティブなど幅広い分野での活用拡大が見込まれます。本記事で紹介した事例のほかにも、スポーツやエンターテインメントなど、さまざまな分野での活用も期待されています。マルチモーダルAIとその進歩は、現在、最も注目すべきトレンド技術のひとつであるといえます。
<コラム>生成AI(Generative AI)とは
生成AIは、機械学習*3の一種である深層学習*4を活用しており(図1)、人が用意したテキストや画像などのデータから特徴を抽出し、その特徴をもとに複数の形式のデータ(テキスト、画像、動画、音声など)を自動的に生成可能とする点が最大の特長になります。もともと、従来のAIでは出力できるデータ形式は極めて限定されており、何らかのコンテンツを生成すること自体が困難でした。多様なデータを生成する生成AIの出現により、AIによる人間の能力拡張や、AIが人間を代替する技術的特異点(シンギュラリティ)の到来について、本格的な議論が行われるようになりました。
このことから、生成AIは、従来のAIとは一線を画す、革新的なAIといってもよいでしょう。
*3 機械(コンピュータ)が、データから特徴やパターンなどの関係性を学習し、予測や識別などを可能とするAI。
*4 従来の機械学習AIと比して、データからのより高度な特徴抽出や、より複雑なパターン認識などを可能とするAIであり、「ディープニューラルネットワーク」がその代表例です。

以下、もう少し生成AIでできることを従来のAIと比較しながら整理しました。
表1に示すように、データにはテキスト、静止画、動画(静止画の集まり)、音声などがあり、従来のAIは、たとえばテキストデータを使って会話や予測をする、動画データを使って識別をするといった能力があります(表2)。一方、生成AIでは、主にテキストデータを使って、テキストはもとより、画像、動画、音声という異なる形式・種類のデータ・コンテンツを生成することができます(表2・表3)。多様なコンテンツを創出できるという点で、生成AIはこれまでにない革新的な機能をもっているといってもよいでしょう。
| データ | 具体例 | |
|---|---|---|
| テキスト(文字) | メール文、記事、書面、プログラムなど | |
| 画像(静止画) | 写真、イラストなど | |
| 動画 | 映画、テレビ番組など | |
| 音 | 音声 | ナレーション、電話通話録音など |
| 音楽 | 歌曲、テクノ、BGMなど | |
従来のAI | 新しいAI | |||
|---|---|---|---|---|
会話系AI | 予測系AI | 識別系AI | 実行系AI | 生成系AI*5 |
翻訳や | データ内の異常値 | 異物や不良品の検出、 | 自動運転やロボット | 作曲、 |
*5 生成AIは生成系AIと呼ばれる場合がある。
| 生成されるデータ(出力データ) | 入力データ | 適用事例 |
|---|---|---|
| テキスト: 質問文の回答や文章を要約 | テキスト | レポート、 記事などの生成 |
| 画像(静止画): テキストの内容から画像を生成 | テキスト | イラスト、絵画、 人物モデル写真などの生成 |
| 動画: テキストの内容から動画を生成 | テキスト、または テキストと静止画 | プロモーションビデオ、 アニメーションなどの生成 |
| 音声: 入力したデータ内容(感情や声調など)にそった 新しい音声を生成 | テキスト | ナレーション、 歌声などの生成 |
| 音楽: 入力したデータ内容(ジャンル・歌詞・想定する 作曲家や歌手)にそった新しい音楽データを生成 | テキスト | 楽曲、BGMなどの生成 |
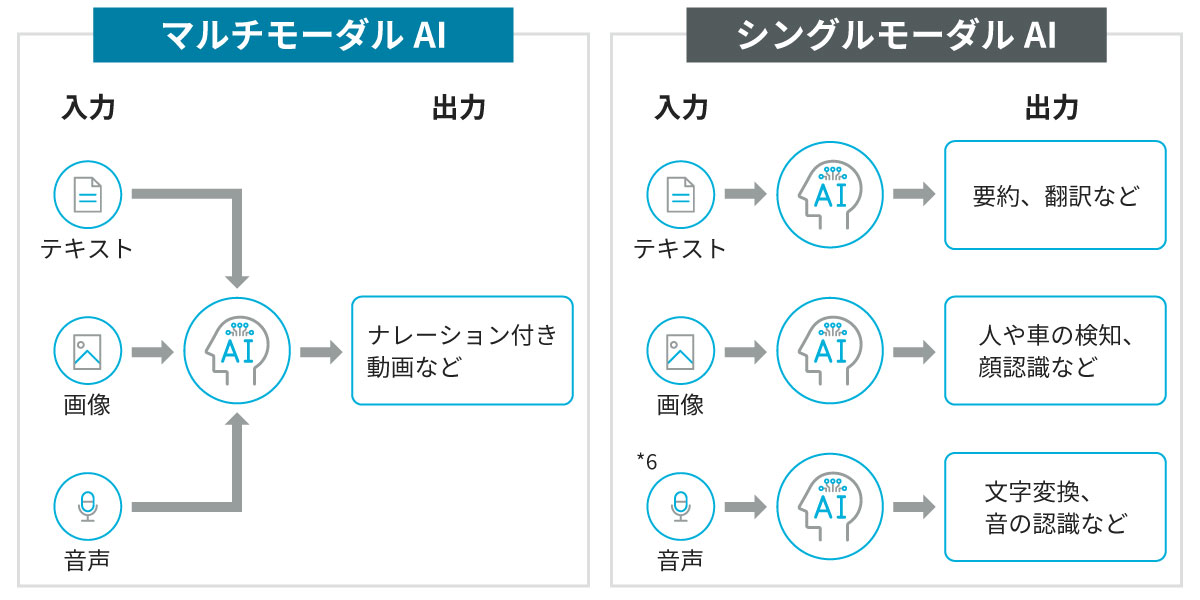
<コラム>マルチモーダルAIとシングルモーダルAI
複数の形式のデータを扱うマルチモーダルAIに対して、従来のAIにみられる単一のデータのみを扱うAIをシングルモーダルAI、またはユニモーダルAIがあります。
マルチモーダルAIとシングルモーダルAIのイメージを図2に示します。テキストのみまたは画像のみ、音声のみといった単一の情報を入力して個別に処理するシングルモーダルAIは、たとえば、Web上のテキスト学習と利用者のテキスト入力を使用する生成AIサービスが該当します。
またネットワークの末端にあるセンサなどの端末(エッジデバイス)でAI推論を行うエッジAIを使った映像または音声の処理も、シングルモーダルAIの例としてあげられます。なお、エッジAIでも、たとえば自動運転などでマルチモーダル化が試行されており、今後、多様な分野でエッジAIのマルチモーダル化が進んでいくことは間違いないでしょう。
*6 上記*2でも記したように、入力が音声、出力がテキストといった入力と出力で異なるデータ形式を扱うことができるAIを、マルチモーダルAIという場合もあります。