
データサイエンティスト×Murata
生成AIを用いた個人情報マスキングの検討事例―人工知能学会全国大会2025
村田製作所(以下、ムラタ)は、人工知能学会全国大会2025(以下、JSAI 2025)において、生成AIを活用した社内検討結果を発表しました(演題名:[1Win4-91] 小規模言語モデル(Small Language Model、以下SLM)による社内文書内個人情報抽出を用いた情報セキュリティ管理手法の検討)。本記事では、発表を行った生成AI CoE(Center of Excellence)リサーチチームのリーダーであるデータ戦略推進部の山口による発表内容の解説と、ムラタにおける生成AIとデータサイエンティストについて紹介します。

*1 生成AI CoEは、生成AIの情報集約・社内活用を推進するために設置された部門横断型の組織。生成AI CoEリサーチチームは、生成AIの先端技術調査と実装をミッションとしている。
1. 人工知能学会全国大会2025(JSAI 2025)における発表内容の解説
1.1 取り組みの背景
1.1.1 生成AIによる社内文書利活用の現状と課題―個人情報の適切な取り扱い
ビッグテック企業が開発・提供するChatGPTをはじめとした生成AIは著しい性能向上を遂げつつあります。なかでも大規模言語モデル(Large Language Model、以下LLM)は高い利便性も相まって、多くの企業で業務効率化を目的にLLMサービスの導入と業務利活用が進んでいます。
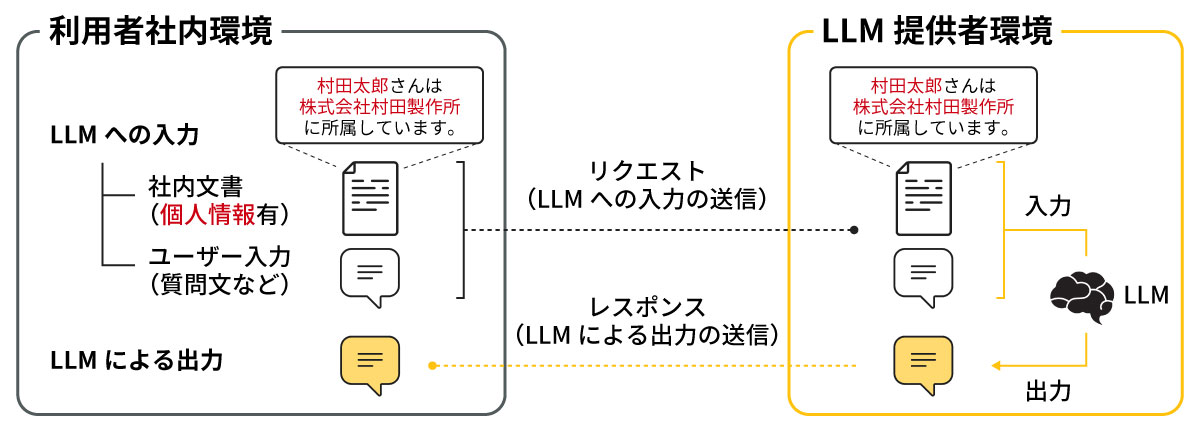
LLMの重要なユースケースのひとつが、社内文書の検索とLLMによる文章生成を組み合わせた社内文書利活用です。これが実現すると、企業内の膨大な文書情報が活用可能となり、業務の効率化や高付加価値化が期待されるため、現在大きな注目を集めています。ただし、LLMサービスの仕組みと現行の法制度を考慮すると、社内文書利活用にLLMを用いる上で個人情報*2の適切な取り扱いは必須であり、各社で対応に迫られている状況です(図1)。
*2 名前や社名、メールアドレスから財務情報に至るまで、特定の個人を識別するデータのことを指す。
1.1.2 生成AIによる社内文書利活用を加速するために―小規模言語モデル(SLM)の活用
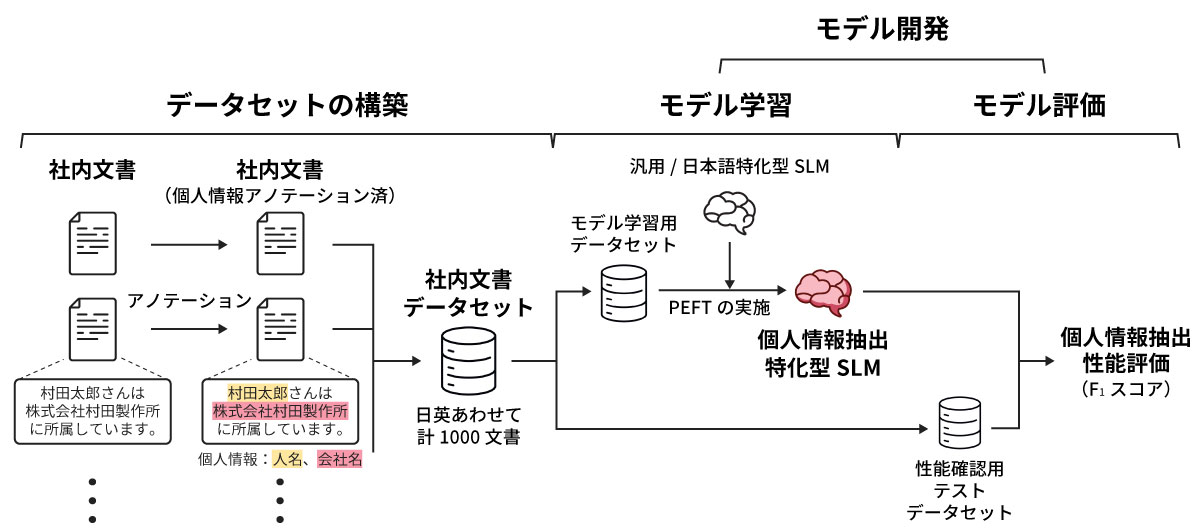
個人情報を適切に取り扱うにはさまざまなアプローチが考えられますが、LLMの入力に着目したアプローチとして、社内文書中の個人情報を事前に抽出・マスキングした後、LLMに入力するフローが考えられます(図2)。当然ですが、このアプローチにおける最大の技術的障壁は、正確かつ自動で社内文書中の個人情報を抽出する部分になります(図2赤枠部)。
今回の社内検討では、オンプレミス環境で社内文書中の個人情報抽出に特化したSLMを開発、その性能確認を行うことで、上記アプローチが実現可能であるか探索することを目的として設定しました。

1.2 検討事項
社内文書中の個人情報をマスキング対象として設定し、図3に示すフローに従い検討を実施しました。社内環境での実施が必須であるため、検討実施事項はすべて、オンプレミスで実行しています。
1.2.1 データセットの構築
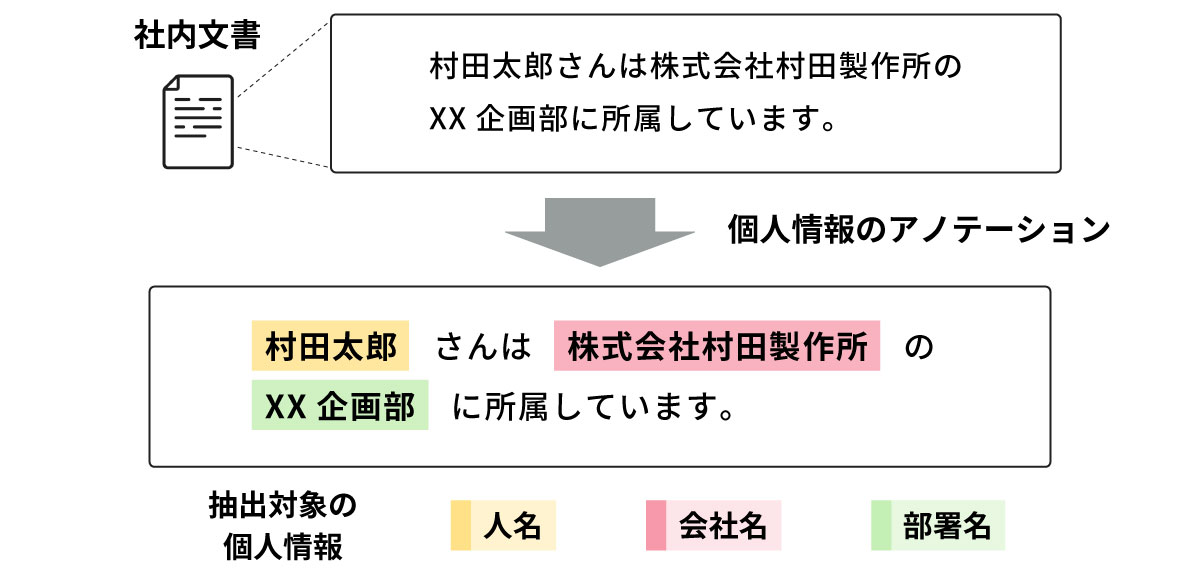
今回の検討には独自データセットの構築が必要不可欠であるため、データセット構築用に個人情報の含まれる計1000件の社内文書(うち、英語515件、日本語485件)を準備しました。抽出対象の個人情報には人名・会社名・部署名の3種類を選定し、これらにアノテーション*3を施すことで、ムラタ独自の社内文書データセットを作成しています(図4)。
*3 解析や学習に必要なラベル情報を付与する工程のこと。
1.2.2 モデル開発(モデル学習と評価)
モデル学習では、オープンソースの汎用・日本語特化型SLM(例えば、Llama系モデル*4)、Parameter-Efficient Fine-Tuning(以下、PEFT)*5、前述の独自データセットの一部を使用することで、社内文書中の個人情報抽出に特化したSLMを開発しました。モデル学習の条件探索では、さまざまなSLMやPEFT手法の検討に加え、Causal Mask*6にも着目し、通常のモデル学習で用いられる条件(CM使用)とは異なる条件(CM未使用)での検討も実施しています(図5)。
*4 ここではMeta社が開発した言語モデル群と、それをもとに改良を加えた言語モデル群のことを指す。
*5 事前学習済モデルを未知のタスクに対して効率的に適応させるための、モデルパラメータ更新(ファインチューニング)手法のひとつ。
*6 文章生成の際、予測対象のトークン(文章を分解した際の最小単位)よりも将来のトークン情報をマスキングする方法。図5左側(Causal Mask使用時)にその概念を示している。

個人情報抽出性能の評価には性能評価用データセットとF1スコア*7を使用、ベースラインモデルの示した性能を基準とし、開発したSLMがどの程度性能が向上しているか評価しました(詳細は表1参照)。
*7 対象の誤検知と見逃しを考慮した性能評価指標。
1.3 検討結果
今回の検討で得られた結果のうち、重要な結論は以下と表1になります。
- 適切なSLM学習条件(SLM、PEFT手法、Causal Mask)下において、ベースラインモデルと比較し、SLMは高い精度で個人情報抽出が可能となる(①、② vs ③~⑥)。
- 社内文書の使用言語によらず、日本語特化型SLMと比較して汎用SLMで個人情報抽出性能が上回る(③、④ vs ⑥)。
- Causal Mask使用時と比較し、未使用時のSLMで個人情報抽出性能が上回る(③ vs ⑤)。
今回は探索的な検討の側面が強いため、SLM学習の条件探索の範囲が限定的でした。今後、より詳細な学習条件探索を行うことで、個人情報抽出におけるSLMの性能向上が期待できると考えています。

*8 PEFT手法に対応。
2. ムラタのデータサイエンティストと今後の展望―発表者インタビュー
ここからは、JSAI 2025での発表を通じて得られた成果や、ムラタのデータサイエンティストとAIについて山口に話を聞きました。
――今回の発表を通して感じたことは?
ムラタがLLMの1ユーザーであるだけに留まらず、社内独自のSLM開発にも積極的に取り組んでいることを広く認知していただけた点は、JSAI 2025での発表を通して得られた大きな成果だと感じています。
また発表者という立場で参加したことで、自身の取り組みについて他社の技術者の方々と多角的な意見交換や深い議論をかわす機会に恵まれました。さまざまな視点からいただいたフィードバックをもとに、今後の技術開発や社内展開をさらに加速していくことができると考えています。
個人レベルの所感になりますが、バイネームで社外の技術者に向けて自身の取り組みを発信できたことは、大きな自信に繋がったと感じています。自身の今後のキャリアにとっても貴重な経験となったため、大変感謝しています。

――ムラタでデータサイエンティストとして働くことについて、どのように感じているか?
ムラタのような製造業の企業では、今回取り扱った文書データに加えて、製造や開発の現場で日々うみだされ蓄積される多種多様かつ膨大なデータが存在しています。こうしたデータに迅速にアクセスし、実際のビジネスや研究開発に活用できる点が大きな魅力だと感じています。ムラタの場合、AIの研究・開発に取り組めるだけでなく、安定した事業基盤のもと、多様な分野の専門家と協働しながら、インパクトのあるプロジェクトに挑戦できる点は大きな強みです。自身の所属する部門横断組織である生成AI CoEが、まさにそのような環境になっていると実感しています。
――ムラタのデータサイエンティストとして果たすべきミッションとは?
生成AIの出現によりデータサイエンティストが取り扱う技術領域は大きくシフトしたものの、データサイエンティストに求められる役割、すなわちAIで会社や事業に貢献することは不変であると感じています。これからAIにより企業が競争力を高めていくには、第三者が提供するAIをただ使うだけでなく、AIを各社独自に最適化することが必須です。この点を達成することが、自身を含めたデータサイエンティストの大きなミッションであると自任しています。
――最後に、今後の展望について。

今回の発表を通して、上記ミッションの達成にはAI領域において積極的に取り組みを発信することでムラタのプレゼンスを高めることに加え、さまざまな技術者とネットワーク構築・議論・意見交換を行うことが重要であることを、改めて認識することができました。自身の取り組みで少しでもムラタに貢献できるよう、今後も学会発表などの取り組みを継続していきたいと考えています。
3. まとめ―編集後記
今回の発表およびインタビューでは、生成AIによる社内文書の利活用促進に向けた社内検討の実例だけでなく、JSAI 2025での発表から得られたことや、ムラタにおけるデータサイエンティストについて、発表者の所感を交えて紹介しました。
こうした技術開発や情報発信の背景には、従業員の主体的な挑戦を尊重し、現場からの提案や取り組みを後押しする企業風土があります。2025年6月には、従業員の提案をきっかけとして、山口を含むデータサイエンティストチームが国際的なデータサイエンスコンペティション「RecSys Challenge 2025」に参加したのはその一例で、結果として好成績を収めることに成功しました。ムラタとともに成長を続けるデータサイエンティストのさらなる活躍が期待されます。
※この記事の内容は、記事公開日時点の情報です。組織の名称などは変更となる場合があります。
