
Data Science × Murata
Case Study of Masking Personally Identifiable Information Using Generative AI - Annual Conference of the Japanese Society for Artificial Intelligence 2025
Murata Manufacturing (hereafter, "Murata") presented the results of an internal study using generative AI at the 2025 conference of the Japanese Society for Artificial Intelligence (hereafter, "JSAI 2025") (Presentation title: [1Win4-91] A Study on Information Security Management Techniques for Extracting Personally Identifiable Information in Internal Documents Using Small Language Models). This article provides an explanation of the presentation given by Yamaguchi of the Data & Analytics Department, who is leader of the Generative AI CoE (Center of Excellence) Research Team, and discusses the generative AI initiatives and data scientists at Murata.

*1 The Generative AI CoE is a cross-departmental organization that was established to promote the aggregation of information about generative AI and its use within Murata. The mission of the Generative AI CoE Research Team is to survey and implement cutting-edge generative AI technologies.
1. Explanation of the Presentation Given at the 2025 Conference of the Japanese Society for Artificial Intelligence (JSAI 2025)
1.1 Background of the initiative
1.1.1 Current state and issues regarding the utilization and application of internal documents using generative AI - Appropriate handling of personally identifiable information
ChatGPT and other forms of generative AI developed and offered by large tech companies continue to demonstrate remarkable performance improvements. Large Language Models (LLMs) in particular offer a high level of convenience, and many companies are introducing, utilizing, and applying LLM services to improve operational efficiency.
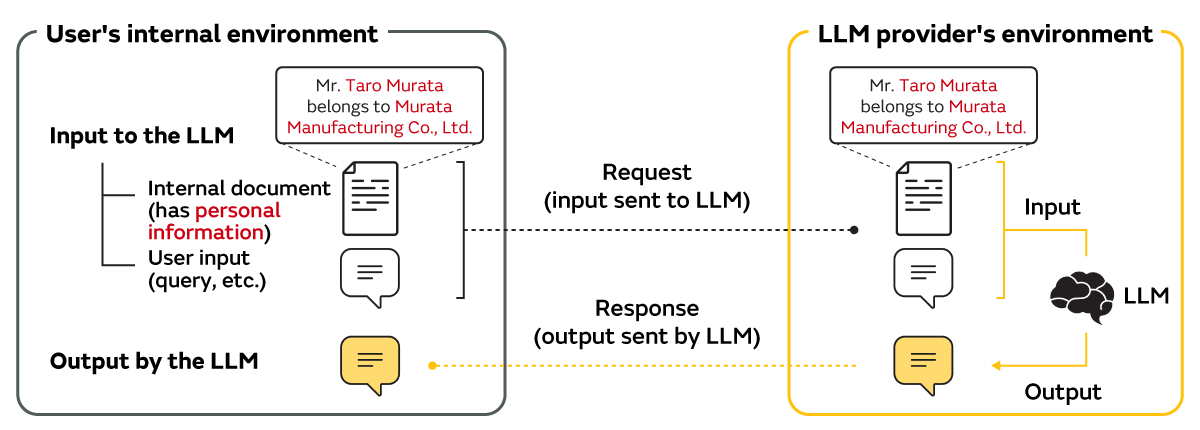
One important use case of LLMs is the utilization and application of internal documents which combines internal document search and LLM-based text generation. Because it is expected that this use case will improve operational efficiency and add value by enabling the utilization of vast amounts of document information if realized, it is currently attracting significant attention. However, given the mechanism of LLM services and the current legal framework, it is essential that personally identifiable information*2 be handled in the appropriate manner when using LLMs for the utilization and application of internal documents, and companies are being forced to respond to this issue (Figure 1).
*2 Refers to data ranging from names of individuals, company names, and email addresses, to financial information that can identify a particular individual.
1.1.2 Accelerating the utilization and application of internal documents using generative AI - Utilizing small language models (SLM)
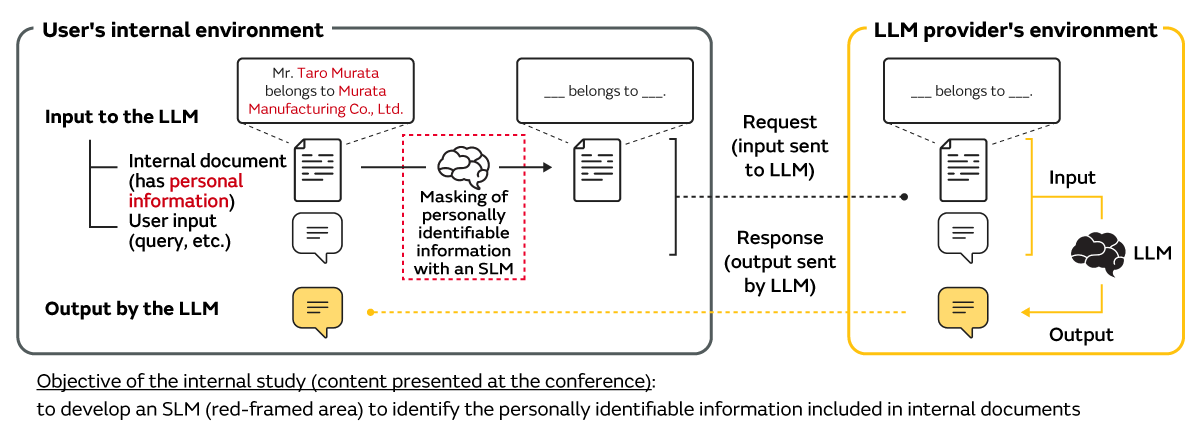
There are various approaches to the appropriate handling of personally identifiable information, and one approach that focuses on the LLM input extracts and masks the personally identifiable information in the internal documents before inputting the information into the LLM (Figure 2). Of course, the greatest technical barrier of this approach lies in automatically and accurately extracting the personally identifiable information in the internal documents (red-framed area in Figure 2).
The objective of this internal study was to develop an SLM that specializes in extracting personally identifiable information from internal documents in an on-premises environment and verify the model's performance to explore the feasibility of the aforementioned approach.
1.2 Study items
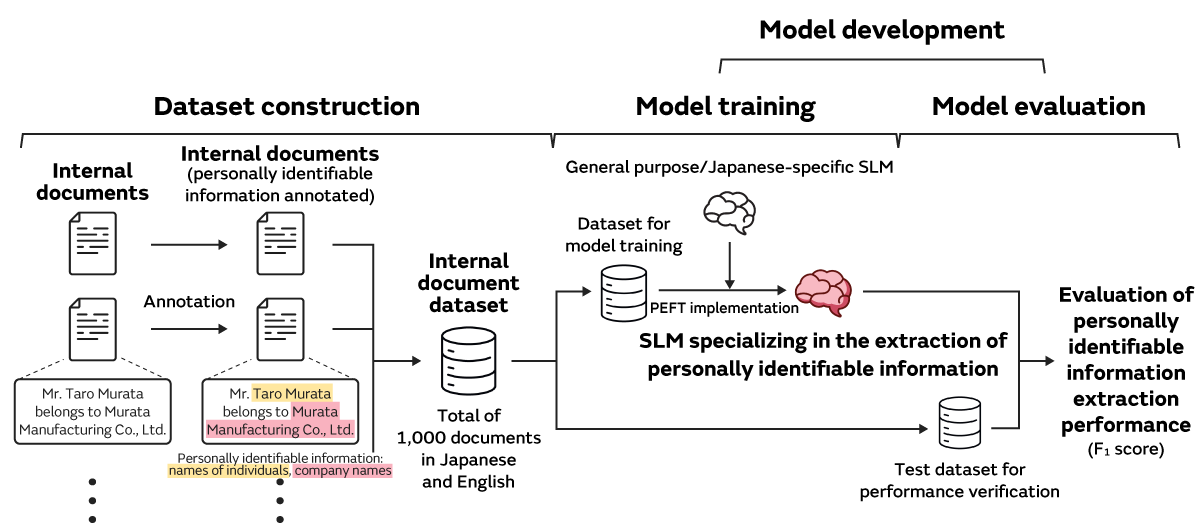
The personally identifiable information within the internal documents was targeted for masking, and the study was conducted according to the flow shown in Figure 3. Since it was essential to conduct the study in an internal environment, all of the study implementation items were executed on-premises.
1.2.1 Dataset construction
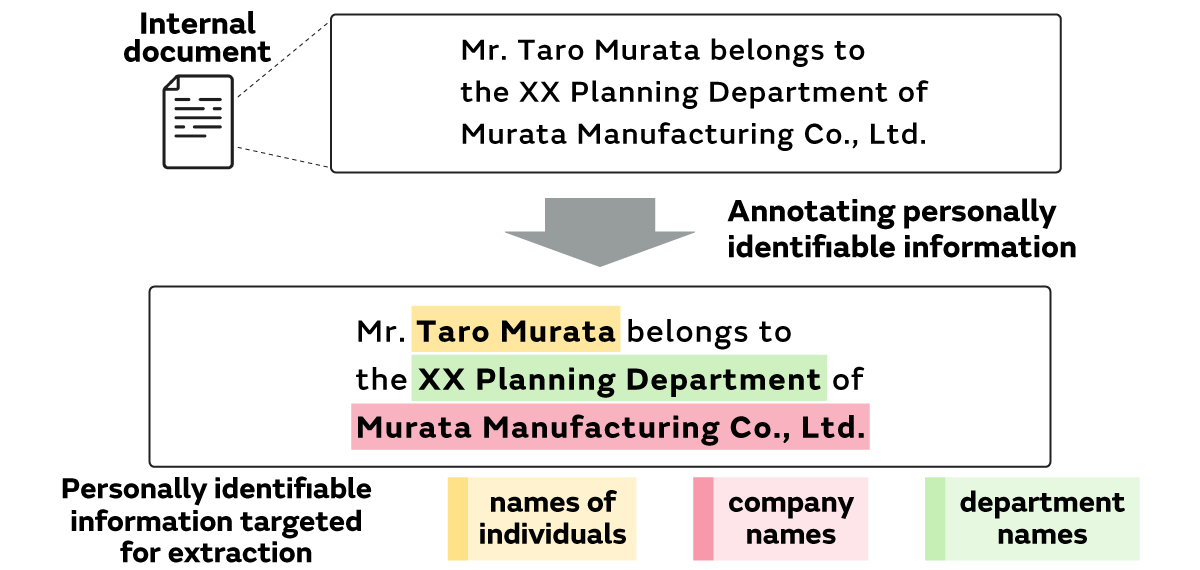
Since it was essential to construct a custom dataset for this study, a total of 1,000 internal documents (515 in English and 485 in Japanese) containing personally identifiable information were prepared for dataset construction. The names of individuals, company names, and department names were selected as the three types of personally identifiable information to be extracted, and they were annotated*3 to create the custom Murata internal document dataset (Figure 4).
*3 Refers to the process of assigning labels needed for analysis and training.
1.2.2 Model development (model training and evaluation)
During the model training, an SLM specializing in the extraction of personally identifiable information from internal documents was developed by using open source general purpose/Japanese-specific SLMs (for example, the Llama series of models*4), Parameter-Efficient Fine-Tuning (PEFT)*5, and part of the aforementioned custom dataset. In exploring the conditions for model training, the team focused on Causal Mask (CM)*6 in addition to studying various SLM and PEFT methods, and carried out studies under conditions (without CM) that differed from the conditions used (with CM) in typical model training (Figure 5).
*4 Refers here to the series of language models developed by Meta and language models that incorporate improvements to those models.
*5 One method of model parameter updating (fine tuning) for efficiently adapting a pre-trained model to unknown tasks.
*6 A method of masking future token (smallest unit when deconstructing text) information instead of the token to be predicted when generating text. This concept is shown on the left side of Figure 5 (when using Causal Mask).

To evaluate the performance of the personally identifiable information extraction, a performance evaluation dataset and F1 score*7 were used, and the developed SLM was evaluated according to how much the performance improved in reference to the performance indicated by the baseline model (see Table 1 for details).
*7 A performance evaluation indicator that considers false positives and false negatives.
1.3 Study results
The important conclusions within the results of this study are shown below and in Table 1.
- Under the appropriate SLM training conditions (SLM, PEFT method, Causal Mask), the SLM can extract personally identifiable information with high precision compared to the baseline model ((1), (2) vs. (3) - (6)).
- Regardless of the language used in the internal document, the performance of a general purpose SLM in extracting personally identifiable information exceeds that of the Japanese-specific SLM ((3), (4) vs. (6)).
- The performance of an SLM in extracting personally identifiable information when not using Causal Mask is higher than when using the Causal Mask ((3) vs. (5)).
Because the focus of this study was largely exploratory, the scope for exploring SLM training conditions was limited. Going forward, we hope to improve the SLM performance in extracting personally identifiable information by exploring the training conditions in a more detailed manner.
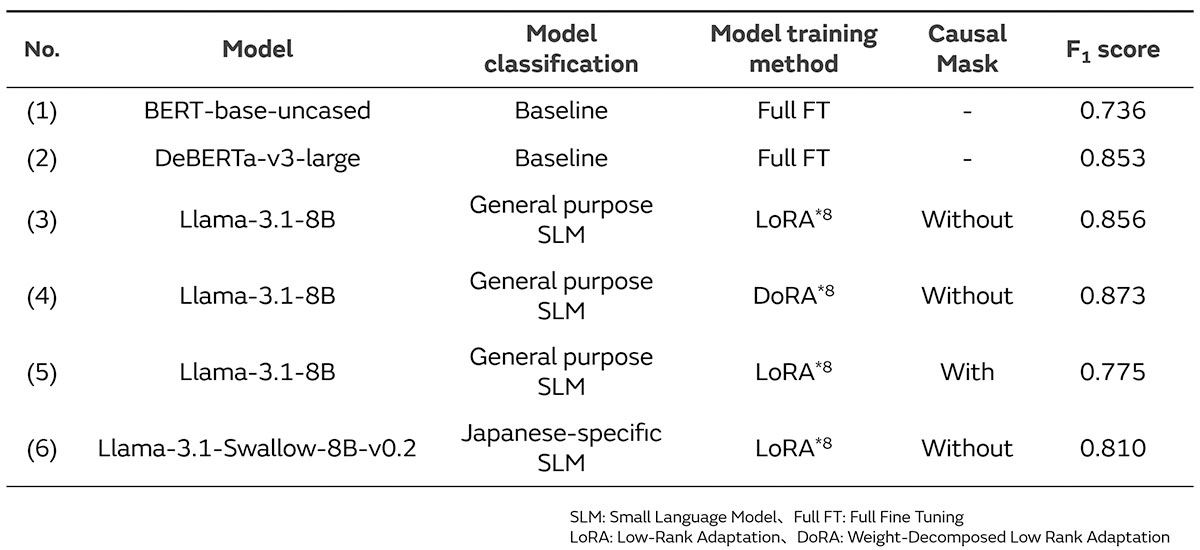
*8 Supports the PEFT method.
2. Murata's Data Scientists and the Future Outlook - An Interview with the Presenter
We spoke with Yamaguchi about the results achieved from giving the JSAI 2025 presentation and Murata's data scientists and AI.
--What were your impressions of the presentation?
I feel that a major achievement of the JSAI 2025 presentation is that many people are now broadly aware that Murata is not just a user of LLMs but is actively developing its own in-house SLMs.
Furthermore, participating as a presenter gave me the opportunity to talk in depth about my own efforts and engage in a multifaceted exchange of opinions with engineers from other companies. Based on the feedback that I received from various perspectives, I believe that we can further accelerate future technology development and internal deployment.
While this is my personal opinion, I feel that being able to individually present my ideas to engineers outside of the company gave me a great deal of confidence. This has been an extremely valuable experience for my future career, and I am truly grateful.

--What are your thoughts about working at Murata as a data scientist?
At a manufacturing company such as Murata, there is a massive amount of diverse data being generated and accumulated every day at the manufacturing and development sites in addition to the document data handled in this recent study. I feel that the ability to quickly access such data and apply it to actual business and research and development is very attractive. In the case of Murata, one of its major strengths is being able to not only engage in AI research and development but also tackle impactful projects while collaborating with experts in diverse fields on a stable business foundation. I feel that the Generative AI CoE, the cross-departmental organization that I belong to, is truly such an environment.
--What is the mission of a Murata data scientist?
Although the technology areas handled by data scientists have significantly shifted with the emergence of generative AI, I feel that the role expected of data scientists, namely to contribute to their companies and businesses with AI, remains the same. In order for companies to increase their competitiveness going forward, it will be essential for each company to not only use the AI solutions provided by third parties but also optimize AI in their own ways. I believe that achieving this goal is a major mission for data scientists including myself.
--In closing, what is your perspective on the future?

Through this presentation, I recognized once again that in order to achieve the aforementioned mission, it is important to build networks, engage in discussions, and exchange opinions with various engineers in addition to increasing Murata's presence by actively disseminating our efforts in the AI field. I would like to continue presenting at conferences, etc., in the hopes that I may contribute to Murata in some small way through my efforts.
3. Summary - Editorial Note
In this presentation and interview, we introduced not only an actual example of an internal study aimed at promoting the utilization and application of internal documents with generative AI but also learned about the presenter's thoughts on what they learned from the JSAI 2025 presentation and what it is like to be a data scientist at Murata.
Behind this technological development and information dissemination lies a corporate culture that respects the independent efforts of employees to tackle challenges and encourages proposals and initiatives from those working in the field. The participation by Yamaguchi and the data scientist team in the "RecSys Challenge 2025" international data science competition, held in June 2025, based on an employee proposal is one such example, which successfully led to a strong performance as a result. We look forward to hearing about the future successes of the data scientists as they continue to grow with Murata.
*The content of this article is based on information as of the date of publication. Organization names and other details may be subject to change.
Related articles
- Take a Behind-the-scenes Look at the In-house Development and Future Outlook for the "Murata Coworker" Generative AI Product With the Product Manager - Annual Conference of the Japanese Society for Artificial Intelligence, 2025
- A Report on Murata Manufacturing's Data Science Case Study Presentations and Corporate Booth - Annual Conference of Japanese Society for Artificial Intelligence, 2024
- Murata Manufacturing Data Scientists Discuss the Power of Practical Application