
数据科学×Murata
利用生成式人工智能进行个人信息屏蔽的研究事例―日本人工智能学会全国大会2025
村田制作所(以下简称村田)在日本人工智能学会全国大会2025(以下简称JSAI 2025)上发表了其利用生成式人工智能进行公司内部研究的结果(演讲题目:使用通过[1Win4-91]小规模语言模型(Small Language Model,以下简称SLM)从公司内部文档中提取个人信息的信息安全管理方法的研究)。本文将对进行发表的生成式人工智能CoE(Center of Excellence)研究团队负责人——数据战略推进部的山口发表的内容进行解说,并对村田的生成式人工智能和数据科学家进行相关介绍。

*1 生成式人工智能CoE是一个跨部门组织,设置该组织的目的是推进生成式人工智能的信息收集和公司内部应用。生成式人工智能CoE研究团队的任务是进行生成式人工智能的前沿技术调查和应用。
1. 在日本人工智能学会全国大会2025(JSAI 2025)上发表的内容解说
1.1 举措背景
1.1.1 通过生成式人工智能进行公司内部文档利用的现状与问题―个人信息的妥善处理
大型科技公司开发和提供的ChatGPT等生成式人工智能的性能在不断显著增强。其中,尤其是大规模语言模型(Large Language Model,以下简称为LLM)的使用非常便利,许多公司正在推进引进LLM服务并将其用于业务以提高业务效率。
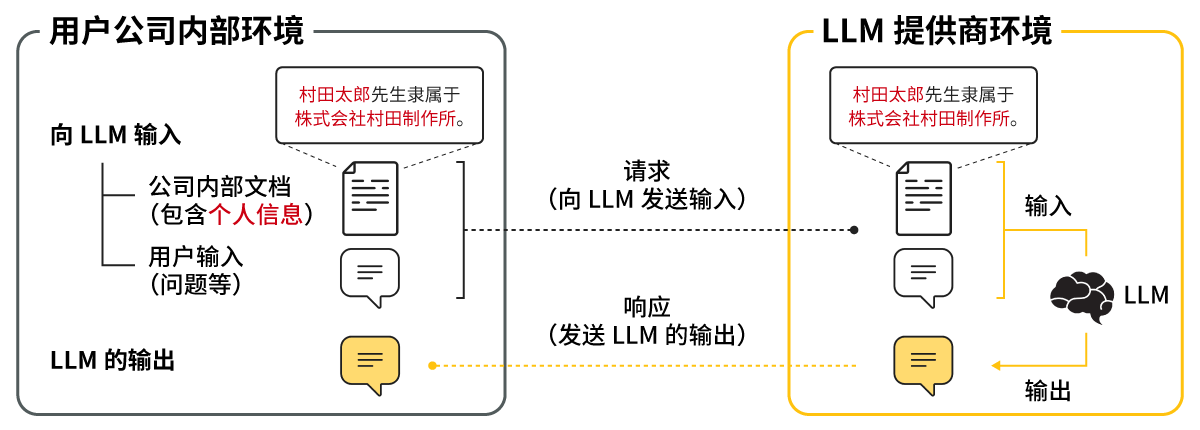
LLM的一个重要用例是将公司内部文档搜索与基于LLM的文本生成相结合的公司内部文档利用。如果能实现,企业内部的海量文档信息将得以充分利用,有望提高业务效率并创造高附加值,因此正在受到普遍关注。然而,考虑到LLM服务机制和现行的法律制度,将LLM用于公司内部文档利用时,需要妥善处理个人信息*2,各家公司都在忙于解决这一问题(图1)。
*2 指能够识别特定个人的数据,包括从个人姓名、公司名称、电子邮件地址到财务信息的多种信息。
1.1.2 为了利用生成式人工智能加速公司内部文档利用―利用小规模语言模型(SLM)
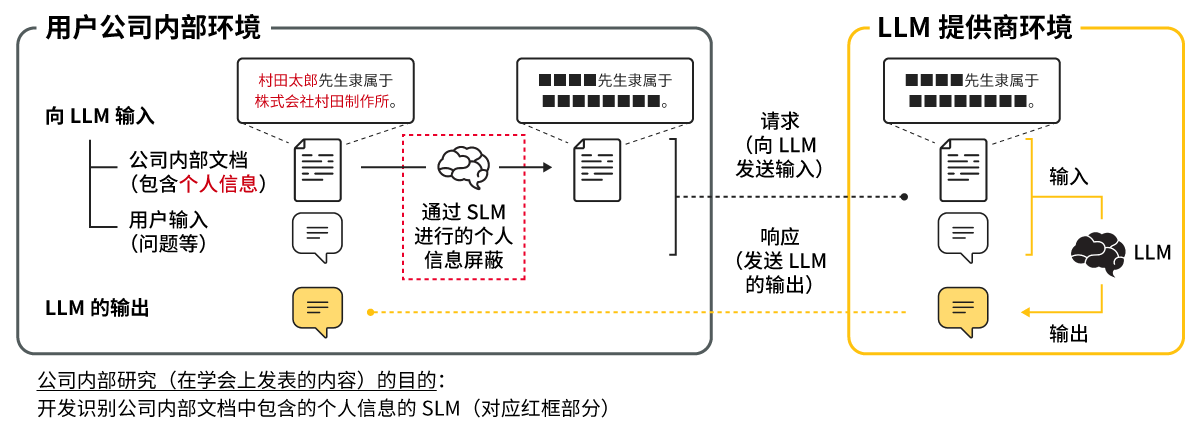
妥善处理个人信息的方法多种多样。其中一种是着眼于LLM输入的方法,这种方法的流程是事先从公司内部文档中提取并屏蔽个人信息,然后将其输入到LLM中(图2)。当然,这种方法的一大技术障碍是如何准确、自动地从公司内部文档中提取个人信息(图2中的红框部分)。
在此次公司内部研究中,我们将研究目的设定为开发一种专门用于在本地环境从公司内部文档中提取个人信息的SLM,并通过对其性能进行确认来探索上述法的可行性。
1.2 研究事项
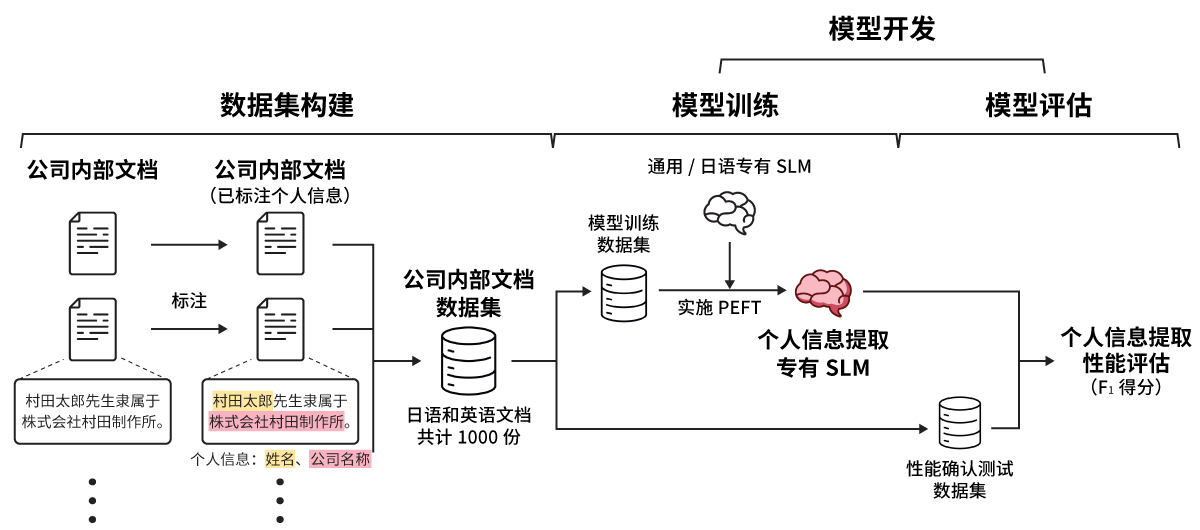
我们将公司内部文档中的个人信息设定为屏蔽对象,并按照图3所示的流程进行了研究。由于需要在公司内部环境中实施,因此全部研究事项均在本地实施。
1.2.1 数据集构建
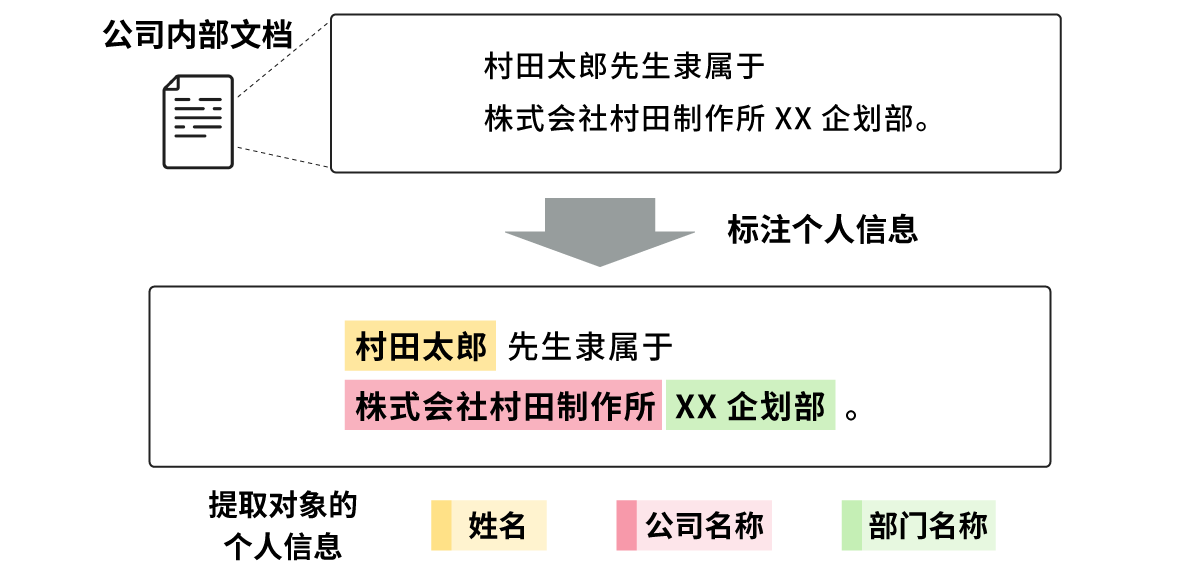
此次研究需要构建专有的数据集,因此我们准备了总计1000份包含个人信息的公司内部文档(其中,英语515份,日语485份)用于构建数据集。我们选择了三种类型的提取对象个人信息:姓名、公司名称和部门名称,并对这些信息进行了标注*3,创建了村田专有的公司内部文档数据集(图4)。
*3 指付与解析和训练所需的标签信息的工序。
1.2.2 模型开发(模型训练与评估)
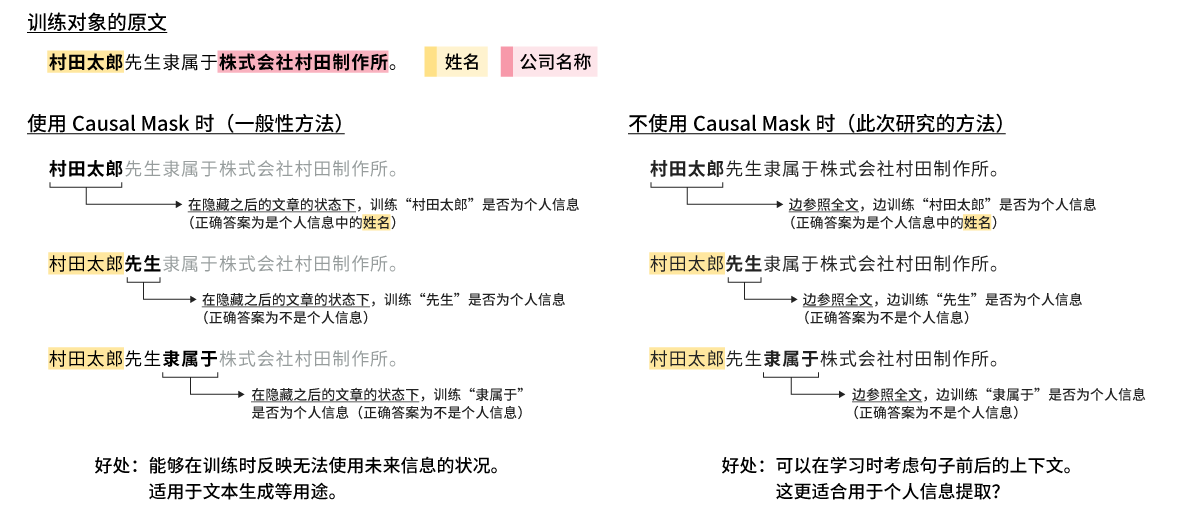
在模型训练方面,我们通过利用开源的通用和日语专有SLM(例如基于Llama的系列模型*4)、Parameter-Efficient Fine-Tuning(PEFT)*5以及上述专有数据集的一部分,开发了专门用于从公司内部文档中提取个人信息的SLM。在探索模型训练条件时,除了研究多种SLM和PEFT方法外,我们还着眼于Causal Mask*6,并在与常规模型训练条件(使用CM)不同的条件下(不使用CM)进行了研究(图5)。
*4 在这里指Meta公司开发的语言模型系列以及基于这些模型系列进行改进后的语言模型系列。
*5 一种模型参数更新(微调)方法,用于将已进行事先训练的模型有效地适应到未知任务。
*6 一种在文本生成过程中对预计对象令牌(文本分解时的下限单位)之后的令牌信息进行屏蔽的方法。其概念如图5左侧(使用Causal Mask时)所示。
为了评估个人信息提取的性能,我们使用了性能评估数据集和F1得分*7,并以基线模型所展现的性能为基准,对开发的SLM在多大程度上增强了性能进行了评估(详情请参照表1)。
*7 考虑了对象误检和漏检后的性能评估指标。
1.3 研究结果
在此次研究得到的结果当中,重要的结论为以下及表1所示内容。
- 在适当的SLM训练条件(SLM、PEFT方法、Causal Mask)下,与基线模型相比,SLM可以更高的准确度提取个人信息(①、② vs ③~⑥)。
- 无论公司内部文档使用何种语言,与日语专有SLM相比,通用SLM的个人信息提取性能都更高(③、④ vs ⑥)。
- 与使用Causal Mask时相比,未使用时SLM的个人信息提取性能更高(③ vs ⑤)。
此次主要为探索性研究,因此SLM训练的条件探索范围有限。我们认为,通过进行更加详细的训练条件探索,SLM在个人信息提取方面的性能有望提高。
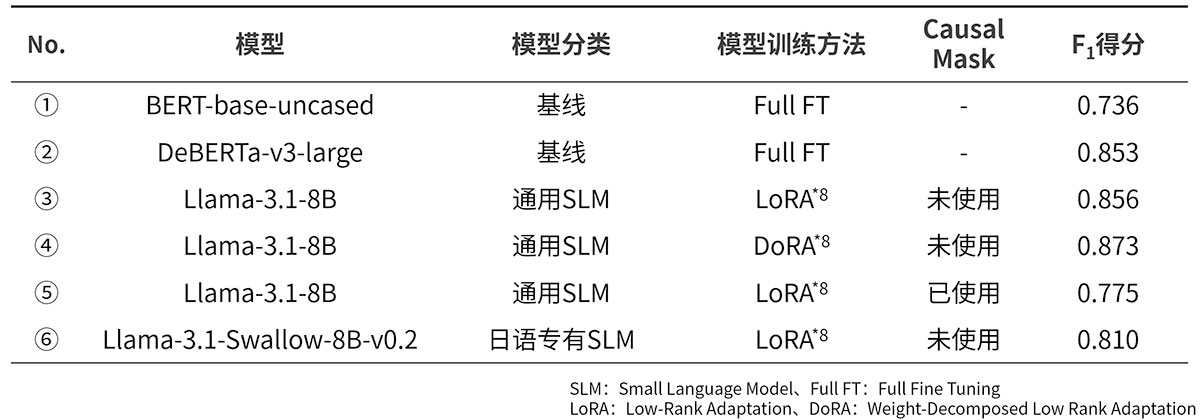
*8 支持PEFT方法。
2. 村田的数据科学家和未来展望―发表者专访
接下来,我们与山口就他通过在JSAI 2025上发表所获得的成果、村田的数据科学家以及人工智能进行了交流。
――您对这次发表有何感想?
我认为,通过在JSAI 2025上发表获得的一大成果在于让更多的人认识到了村田不仅是LLM的1个用户,而且还积极进行公司内部专有的SLM开发。
此外,作为发表者,我很幸运有机会就我的工作与其他公司的技术人员从不同角度交流意见并进行深入讨论。我认为,基于来自多种不同角度的反馈,我们能进一步加快今后的技术开发和公司内部推广。
这只是我的个人看法,但能够指名让我向公司外部的技术人员介绍自己的工作让我感到非常自信。它对我今后的职业生涯也是一次非常宝贵的经验,因此我非常感谢能有这样的机会。

――您对作为一名数据科学家在村田工作有何感受?
在村田这样的制造业企业,除了此次处理的文档数据外,还有在生产和开发现场每天生成和积累的多种海量数据。能够迅速访问这些数据并将其应用于实际业务和研发,对我来说具有非常大的吸引力。在村田,不仅可以从事人工智能的研发工作,而且能够在稳定的业务基础上,与多个领域的专家合作,共同挑战有影响力的项目,这是一个非常大的优势。我认为,我所属的跨部门组织——生成式人工智能CoE就提供了这样的环境。
――作为村田数据科学家应该完成的任务是什么?
虽然生成式人工智能的出现显著改变了数据科学家所涉足的技术领域,但我认为,数据科学家的作用——通过人工智能为公司和事业做贡献——一直没有改变。今后,企业要想通过人工智能增强竞争力,不仅要利用第三方提供的人工智能,还要将人工智能优化成每家公司专有的人工智能。我认为,实现这一点是包括我在内的数据科学家的一项重要任务。
――最后,您对未来有什么展望?

通过此次发表,让我再次认识到,为了完成上述任务,不仅要通过积极宣传村田在人工智能领域的举措来增强村田的影响力,还要与多种多样的技术人员建立人脉,进行讨论,交流意见,这非常重要。我希望今后能够继续实施学会发表等举措,通过自己的努力为村田贡献一份力量。
3. 总结―编后记
在此次发表及专访中,除了为了利用生成式人工智能促使公司内部文档利用而进行的公司内部研究实例之外,我们还对在JSAI 2025上的发表获得的成果、村田的数据科学家、发表者的感想进行了介绍。
这些技术开发和信息传播的背后,是尊重员工积极挑战的主动性、支持来自现场的建议和举措的企业文化。例如,2025年6月,在一位员工的建议下,包括山口在内的数据科学家团队参加了国际数据科学竞赛“RecSys Challenge 2025”,并成功地取得了好成绩。我们希望与村田共同成长的数据科学家取得更大的成功。
※本文内容为截至发布之日的信息。组织名称等可能会发生变更。