
通过传感器数据×数据解析进行的设备维护DX
第2篇 在预估性维护中进行数据解析的方法
在“通过传感器数据×数据解析进行的设备维护DX”系列的第1篇文章中,我们就近年来特别是在设备维护中特别受到关注的预估性维护(Predictive Maintenance;PdM),对其概要和引进时的要点进行了解说。
引进预估性维护时应该考虑的要点有多个,其中之一是“选择合适的数据解析方法”。在预估性维护中进行数据解析的目的是正确检测出传感器数据中出现的设备劣化迹象。为此,仔细观察传感器数据,在理解设备劣化引起的波动模式的特征的基础上,选择适合这些特征的数据解析方法非常重要。
本文是“通过传感器数据×数据解析进行的设备维护DX”系列的第2篇文章,以预估性维护的数据解析为重点,对常用的数据解析技术和方法,以及进行数据解析的一系列流程(从收集传感器数据到选择数据解析方法)进行通俗易懂地解说。
INDEX
1. 预估性维护中使用的数据解析技术和具体方法
表1显示了预估性维护中常用的数据解析技术列表。除了表1所示的数据解析技术外,还有对故障部位和种类进行分类的故障分类方法等,但是,如果打算从现在开始引进设备维护DX,暂时考虑表1所示的技术即可。另一方面,关于具体方法,以下所示的方法只是一部分,实际上,人们已经提出了多种多样的方法,因此,可供选择的方法有很多。
数据解析技术 | 特征 | 具体方法示例*1 |
|---|---|---|
离群值检测 | 根据周围数据点的数量进行判断 | ・k近邻法 |
异常检测 | 根据与正常(异常)模式之间的偏离程度进行判断 | ・k近邻法 |
变化检测 | 根据与之前时刻的模式之间的偏离程度进行判断 | ・k近邻法 |
*1 在本文中,我们将以进行数据解析的一些列方法为重点进行解说,因此,这里省略对具体方法的说明。
然而,直接从表1选择数据解析技术和具体方法并不是一个好主意。因为在很多情况下,最初选择的方法并不合适,导致大量返工,结果浪费了讨论时花费的成本和时间。
为了实现通过传感器数据×数据解析进行的预估性维护,重要的是从上表所示的技术和方法当中选择并适用维护对象设备及从中获得的传感器数据的技术和方法。
2. 在预估性维护中进行数据解析的方法
对预估性维护中使用的数据进行解析时,要按照什么步骤进行呢?下面我们根据图1对其流程进行说明。

[Step 1]通过传感器进行数据收集
如果没有用于解析的传感器数据,数据解析就无法开始。所以要根据需要维护的对象设备选择并设置合适的传感器,并使其处于能正确收集原本想要的数据的状态。
[Step 2]发现异常模式并将其分类
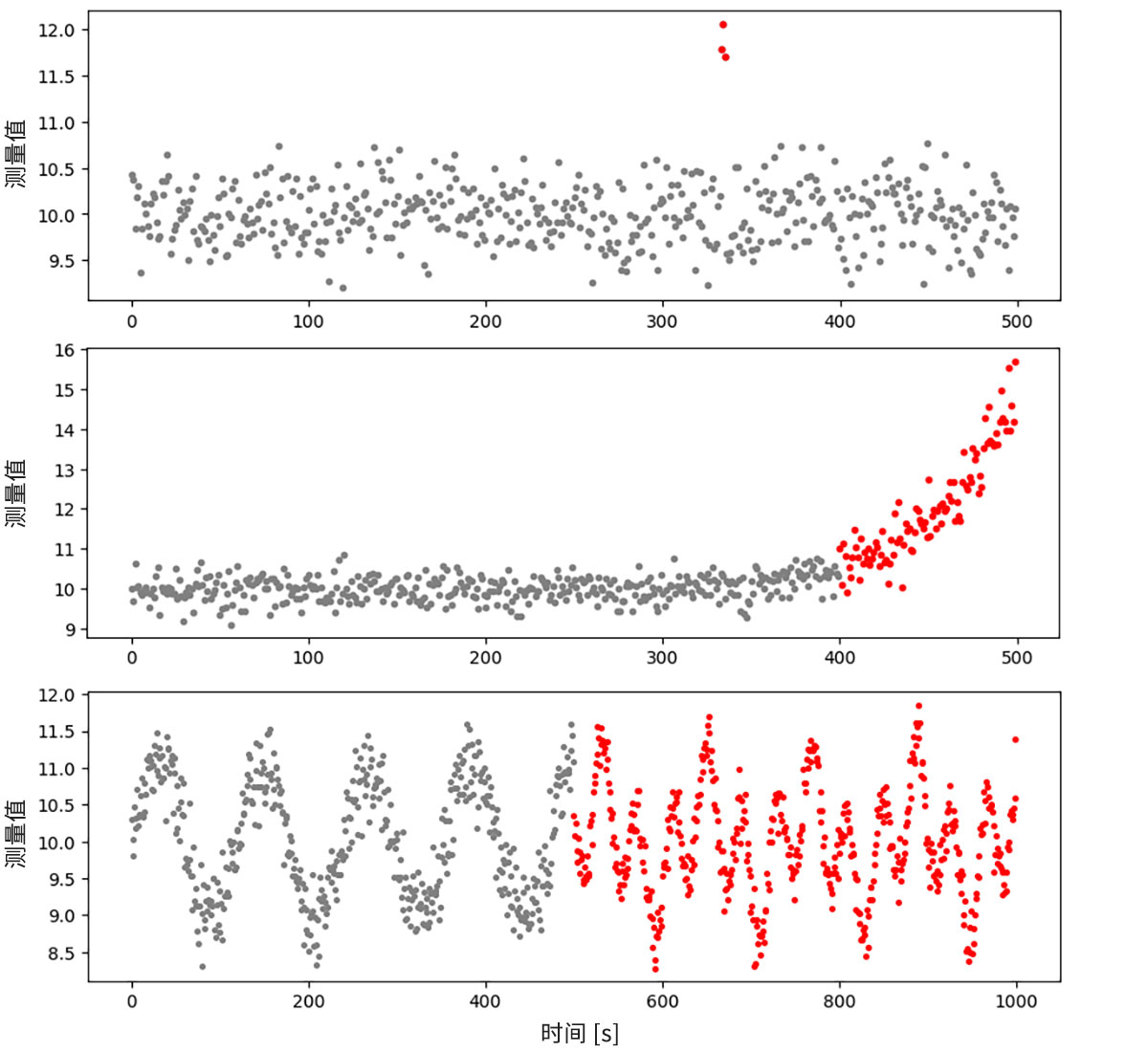
下面要进行的是发现收集的数据中出现的异常*2模式并对它们进行分类。作为示例,图2显示了传感器数据中出现的典型异常模式。
进行Step 2的方法有很多种,但数据可视化和目视观察是非常基本且有效的方法。本步骤中观察到的异常被分类为图2中的哪种模式是选择更合适的数据解析方法时的重要基准(参照Step 3)。
下面,我们将假设已经发现了想要检测的原因(设备劣化或故障等)引起的异常*2并已对其进行分类,然后继续讨论。
*2 本文中作为对象的“异常”
传感器数据值中出现的异常是“与设备正常稼动状态下测量的传感器数据值和时间序列趋势不同的全部情况”,有以下2种含义。
(a)因设备劣化或故障引起的变化而导致的异常
(b)由于上述(a)以外的因素引起的变化而导致的异常
(例如,由于运营改进或设备维修而导致人员、生产机械、材料、方法等的变化)
在预估性维护中,经常会将(a)中的异常作为监测对象,因此本文将以(a)中的异常为对象进行解说。
另外,在实际运营中,需要掌握传感器数据值中出现的变化是(a)的异常还是(b)的异常。然而,一般情况下,仅根据传感器数据难以判断发生了哪种异常,因此需要适当地参考维护记录等进行判断。
[Step 3]选择数据解析技术
在Step 2中掌握了异常模式后,就进入了选择数据解析技术的阶段。如上所述,出现的异常模式是选择要适用的数据解析技术时的重要基准,因此,下面将介绍适合图2所示的每种模式的数据解析技术。
(1)作为突发性离群值出现的异常(图2上段)
如果异常作为突发性离群值出现,则考虑适用被称为离群值检测的数据解析技术。在离群值检测中,如果对象数据的周围没有数据或数据很少,则判定为异常(图3)。另外,如果可以付与正常的标签,则也可以适用下面的[Step 3](2)中的异常检测。
- 特征:不需要对数据付与正常或异常标签,因此,为适用技术而收集数据的难度较小
- 注意点:将正常数据误判为异常的误检测风险较高
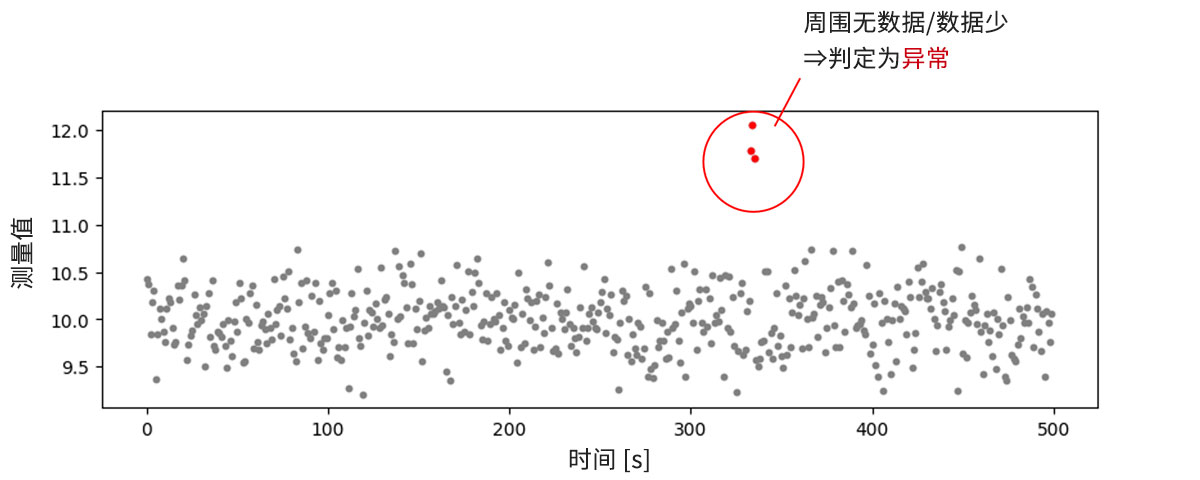
(2)作为漂移出现的异常(图2中段)
如果异常伴随着漂移那样的连续变化,则无法适用离群值检测,应该考虑适用异常检测。在异常检测中,以其从正常模式偏离的程度作为基准进行异常判断(图4)。
按照同样的思路,如果有足够的异常数据,则也可以考虑进行故障检测,即根据与该模式的相似程度来进行异常判断。但在这种情况下,需要在一定程度上覆盖异常数据。这种情况一般不常见,所以适用时要注意。
- 特征:根据与正常模式偏离的程度或相似程度来检测异常,因此可以应对漂移那样的变化
- 注意点:需要明确定义参考源——正常模式并付与标签,因此,与离群值检测相比,数据收集和整理的难度和成本略高
(故障检测时)只有在设备劣化或故障所导致的异常数据能得到充分保障的情况下,才能考虑适用
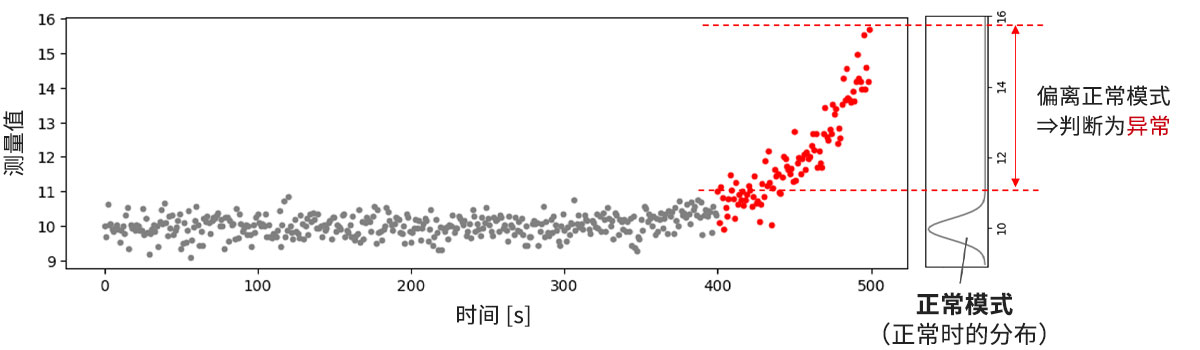
(3)作为趋势的变化出现的异常(图2下段)
如果可能的数据范围与正常稼动时没有显著差异、只有趋势(斜率、周期、变动模式等)发生变化的异常,则可能很难适用仅通过单一数据进行判断的离群值检测或异常检测。在这种情况下,要考虑适用变化检测。
变化检测与上述技术不同,它采用的是一种同时对多个数据进行评估的形式。通过将待判断对象的数据组与稍早时间的数据组进行比较,调查是否存在趋势变化(图5)。
变化检测还包括一种仅在数据的可能范围持续偏离正常操作时进行检测的方法。当由于设备或测量对象的特性原因,即使在正常稼动时也可能出现一次性离群值时,这种方法很有用。
- 特征:专门检测趋势变化在一定程度上连续发生的异常
- 注意点:不适合用于检测突然、一次性发生的异常
[Step 4]选择数据解析方法
选择好数据解析技术后,要选择更具体的方法。涵盖全部方法的选择基准并不现实,因此,这里我们想就选择方法时一般应该考虑的2个要点进行相关介绍。
方法假设的前提条件
将数据遵循特定的分布作为前提的方法是其代表性事例。如果不满足该前提,则可能陷入无法正确检测异常的事态。例如,表1中作为检测异常的具体方法例示的马哈拉诺比斯-田口法是一种可以应用于多种场面的方法,但它以数据服从正态分布为前提。因此,如果只是因为经常被使用的原因而选择这种方法,那么,在对象数据不服从正态分布时,将无法正确检测异常。所以,请务充分确认拥有的数据是否满足前提条件。
方法的解释性
数据解析的最终目的是预估性维护,因此,如果已判断为异常,则要有人类根据该结果来判断是否进行维护。考虑到这一点,在进行维护时,可以说应优先使用对判断为异常的依据容易进行解释的方法。
但是,在某些情况下,需要在方法的解释性与其检测异常能力之间进行权衡。应该优先考虑哪一个取决于具体情况,因此,应当由数据解析人员与预估性维护实施人员进行充分的协调,使双方在相互理解上不会出现分歧。
3. 总结
在本文中,我们对预估性维护中使用的代表性数据解析技术和方法,以及它们的选择流程进行了解说。
选择数据解析方法的诀窍就是不要直接开始选择方法。如果首先仔细确认传感器是否获取了预期数据以及观察到的异常具有哪些特征,那么返工将变得更少。一旦完成了这一步,应该连锁式适用的技术和具体方法就会出现。
近来,范围往往集中在机器学习、深度学习等解析方法本身,但要通过“传感器数据×数据解析”实现预估性维护,不仅要关注解析方法本身,还要牢牢掌握选择适当的方法时应该掌握的基本事项,可以说,这比什么都重要。